A study of Google search results by anti-tracking rival DuckDuckGo has suggested that escaping the so-called ‘filter bubble’ of personalized online searches is a perniciously hard problem for the put upon Internet consumer who just wants to carve out a little unbiased space online, free from the suggestive taint of algorithmic fingers.
DDG reckons it’s not possible even for logged out users of Google search, who are also browsing in Incognito mode, to prevent their online activity from being used by Google to program — and thus shape — the results they see.
DDG says it found significant variation in Google search results, with most of the participants in the study seeing results that were unique to them — and some seeing links others simply did not.
Results within news and video infoboxes also varied significantly, it found.
While it says there was very little difference for logged out, incognito browsers.
“It’s simply not possible to use Google search and avoid its filter bubble,” it concludes.
Google has responded by counter-claiming that DuckDuckGo’s research is “flawed”.
Degrees of personalization
DuckDuckGo says it carried out the research to test recent claims by Google to have tweaked its algorithms to reduce personalization.
A CNBC report in September, drawing on access provided by Google, letting the reporter sit in on an internal meeting and speak to employees on its algorithm team, suggested that Mountain View is now using only very little personalization to generate search results.
“A query a user comes with usually has so much context that the opportunity for personalization is just very limited,” Google fellow Pandu Nayak, who leads the search ranking team, told CNBC this fall.
On the surface, that would represent a radical reprogramming of Google’s search modus operandi — given the company made “Personalized Search” the default for even logged out users all the way back in 2009.
Announcing the expansion of the feature then Google explained it would ‘customize’ search results for these logged out users via an ‘anonymous cookie’:
This addition enables us to customize search results for you based upon 180 days of search activity linked to an anonymous cookie in your browser. It’s completely separate from your Google Account and Web History (which are only available to signed-in users). You’ll know when we customize results because a “View customizations” link will appear on the top right of the search results page. Clicking the link will let you see how we’ve customized your results and also let you turn off this type of customization.
A couple of years after Google threw the Personalized Search switch, Eli Pariser published his now famous book describing the filter bubble problem. Since then online personalization’s bad press has only grown.
In recent years concern has especially spiked over the horizon-reducing impact of big tech’s subjective funnels on democratic processes, with algorithms carefully engineered to keep serving users more of the same stuff now being widely accused of entrenching partisan opinions, rather than helping broaden people’s horizons.
Especially so where political (and politically charged) topics are concerned. And, well, at the extreme end, algorithmic filter bubbles stand accused of breaking democracy itself — by creating highly effective distribution channels for individually targeted propaganda.
Although there have also been some counter claims floating around academic circles in recent years that imply the echo chamber impact is itself overblown. (Albeit sometimes emanating from institutions that also take funding from tech giants like Google.)
As ever, where the operational opacity of commercial algorithms is concerned, the truth can be a very difficult animal to dig out.
Of course DDG has its own self-interested iron in the fire here — suggesting, as it is, that “Google is influencing what you click” — given it offers an anti-tracking alternative to the eponymous Google search.
But that does not merit an instant dismissal of a finding of major variation in even supposedly ‘incognito’ Google search results.
DDG has also made the data from the study downloadable — and the code it used to analyze the data open source — allowing others to look and draw their own conclusions.
It carried out a similar study in 2012, after the earlier US presidential election — and claimed then to have found that Google’s search had inserted tens of millions of more links for Obama than for Romney in the run-up to that.
It says it wanted to revisit the state of Google search results now, in the wake of the 2016 presidential election that installed Trump in the White House — to see if it could find evidence to back up Google’s claims to have ‘de-personalized’ search.
For the latest study DDG asked 87 volunteers in the US to search for the politically charged topics of “gun control”, “immigration”, and “vaccinations” (in that order) at 9pm ET on Sunday, June 24, 2018 — initially searching in private browsing mode and logged out of Google, and then again without using Incognito mode.
You can read its full write-up of the study results here.
The results ended up being based on 76 users as those searching on mobile were excluded to control for significant variation in the number of displayed infoboxes.
Here’s the topline of what DDG found:
Private browsing mode (and logged out):
- “gun control”: 62 variations with 52/76 participants (68%) seeing unique results.
- “immigration”: 57 variations with 43/76 participants (57%) seeing unique results.
- “vaccinations”: 73 variations with 70/76 participants (92%) seeing unique results.
‘Normal’ mode:
- “gun control”: 58 variations with 45/76 participants (59%) seeing unique results.
- “immigration”: 59 variations with 48/76 participants (63%) seeing unique results.
- “vaccinations”: 73 variations with 70/76 participants (92%) seeing unique results.
DDG’s contention is that truly ‘unbiased’ search results should produce largely the same results.
Yet, by contrast, the search results its volunteers got served were — in the majority — unique. (Ranging from 57% at the low end to a full 92% at the upper end.)
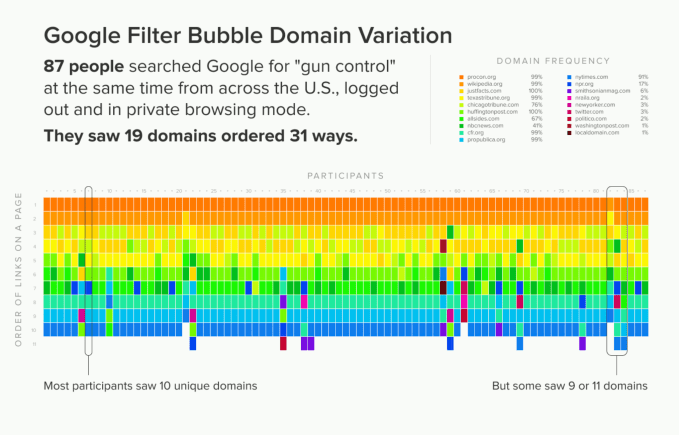
“With no filter bubble, one would expect to see very little variation of search result pages — nearly everyone would see the same single set of results,” it writes. “Instead, most people saw results unique to them. We also found about the same variation in private browsing mode and logged out of Google vs. in normal mode.”
“We often hear of confusion that private browsing mode enables anonymity on the web, but this finding demonstrates that Google tailors search results regardless of browsing mode. People should not be lulled into a false sense of security that so-called “incognito” mode makes them anonymous,” DDG adds.
Google initially declined to provide a statement responding to the study, telling us instead that several factors can contribute to variations in search results — flagging time and location differences among them.
It even suggested results could vary depending on the data center a user query was connected with — potentially introducing some crawler-based micro-lag.
Google also claimed it does not personalize the results of logged out users browsing in Incognito mode based on their signed-in search history.
However the company admited it uses contextual signals to rank results even for logged out users (as that 2009 blog post described) — such as when trying to clarify an ambiguous query.
In which case it said a recent search might be used for disambiguation purposes. (Although it also described this type of contextualization in search as extremely limited, saying it would not account for dramatically different results.)
But with so much variation evident in the DDG volunteer data, there seems little question that Google’s approach very often results in individualized — and sometimes highly individualized — search results.
Some Google users were even served with more or fewer unique domains than others.
Lots of questions naturally flow from this.
Such as: Does Google applying a little ‘ranking contextualization’ sound like an adequately ‘de-personalized’ approach — if the name of the game is popping the filter bubble?
Does it make the served results even marginally less clickable, biased and/or influential?
Or indeed any less ‘rank’ from a privacy perspective… ?
You tell me.
Even the same bunch of links served up in a slightly different configuration has the potential to be majorly significant since the top search link always gets a disproportionate chunk of clicks. (DDG says the no.1 link gets circa 40%.)
And if the topics being Google-searched are especially politically charged even small variations in search results could — at least in theory — contribute to some major democratic impacts.
There is much to chew on.
DDG says it controlled for time- and location-based variation in the served search results by having all participants in the study carry out the search from the US and do so at the very same time.
While it says it controlled for the inclusion of local links (i.e to cancel out any localization-based variation) by bundling such results with a localdomain.com placeholder (and ‘Local Source’ for infoboxes).
Yet even taking steps to control for space-time based variations it still found the majority of Google search results to be unique to the individual.
“These editorialized results are informed by the personal information Google has on you (like your search, browsing, and purchase history), and puts you in a bubble based on what Google’s algorithms think you’re most likely to click on,” it argues.
Google would counter argue that’s ‘contextualizing’, not editorializing.
And that any ‘slight variation’ in results is a natural property of the dynamic nature of its Internet-crawling search response business.
Albeit, as noted above, DDG found some volunteers did not get served certain links (when others did), which sounds rather more significant than ‘slight difference’.
In the statement Google later sent us it describes DDG’s attempts to control for time and location differences as ineffective — and the study as a whole as “flawed” — asserting:
This study’s methodology and conclusions are flawed since they are based on the assumption that any difference in search results are based on personalization. That is simply not true. In fact, there are a number of factors that can lead to slight differences, including time and location, which this study doesn’t appear to have controlled for effectively.
One thing is crystal clear: Google is — and always has been — making decisions that affect what people see.
This capacity is undoubtedly influential, given the majority marketshare captured by Google search. (And the major role Google still plays in shaping what Internet users are exposed to.)
That’s clear even without knowing every detail of how personalized and/or customized these individual Google search results were.
Google’s programming formula remains locked up in a proprietary algorithm box — so we can’t easily (and independently) unpick that.
And this unfortunate ‘techno-opacity’ habit offers convenient cover for all sorts of claim and counter-claim — which can’t really now be detached from the filter bubble problem.
Unless and until we can know exactly how the algorithms work to properly track and quantify impacts.
Also true: Algorithmic accountability is a topic of increasing public and political concern.
Lastly, ‘trust us’ isn’t the great brand mantra for Google it once was.
So the devil may yet get (manually) unchained from all these fuzzy details.