In a statement, Facebook said that Cambridge Analytica has agreed to comply and give Stroz Friedberg access to their servers and systems.
Facebook has also reached out to the whistleblower Christopher Wylie and Aleksandr Kogan, the Cambridge University professor who developed an application which collected data that he then sold to Cambridge Analytica.
Kogan has consented to the audit, but Wylie, who has positioned himself as one of the architects for the data collection scheme before becoming a whistleblower, declined, according to Facebook.
The move comes after a brutal day for Facebook’s stock on the Nasdaq stock exchange. Facebook shares plummeted 7%, erasing roughly $40 billion in market capitalization amid fears that the growing scandal could lead to greater regulation of the social media juggernaut.
Indeed both the Dow Jones Industrial Average and the Nasdaq fell sharply as worries over increased regulations for technology companies ricocheted around trading floors, forcing a sell-off.
“This is part of a comprehensive internal and external review that we are conducting to determine the accuracy of the claims that the Facebook data in question still exists. This is data Cambridge Analytica, SCL, Mr. Wylie, and Mr. Kogan certified to Facebook had been destroyed. If this data still exists, it would be a grave violation of Facebook’s policies and an unacceptable violation of trust and the commitments these groups made,” Facebook said in a statement.
However, as more than one Twitter user noted, this is an instance where they’re trying to close Pandora’s Box but the only thing that the company has left inside is… hope.
We take your = thoughts
Privacy seriously = prayers— Paul Ford (@ftrain) March 17, 2018
The bigger issue is that Facebook had known about the data leak early as two years ago, but did nothing to inform its users — because the violation was not a “breach” of Facebook’s security protocols.
Facebook’s own argument for the protections it now has in place is a sign of its too-little, too-late response to a problem it created for itself with its initial policies.
“We are moving aggressively to determine the accuracy of these claims. We remain committed to vigorously enforcing our policies to protect people’s information. We also want to be clear that today when developers create apps that ask for certain information from people, we conduct a robust review to identify potential policy violations and to assess whether the app has a legitimate use for the data,” the company said in a statement. “We actually reject a significant number of apps through this process. Kogan’s app would not be permitted access to detailed friends’ data today.”
It doesn’t take a billionaire Harvard dropout genius to know that allowing third parties to access personal data without an individual’s consent is shady. And that’s what Facebook’s policies used to allow by letting Facebook “friends” basically authorize the use of a user’s personal data for them.
As we noted when the API changes first took effect in 2015:
Apps don’t have to delete data they’ve already pulled. If someone gave your data to an app, it could go on using it. However, if you request that a developer delete your data, it has to. However, how you submit those requests could be through a form, via email, or in other ways that vary app to app. You can also always go to your App Privacy Settings and remove permissions for an app to pull more data about you in the future.
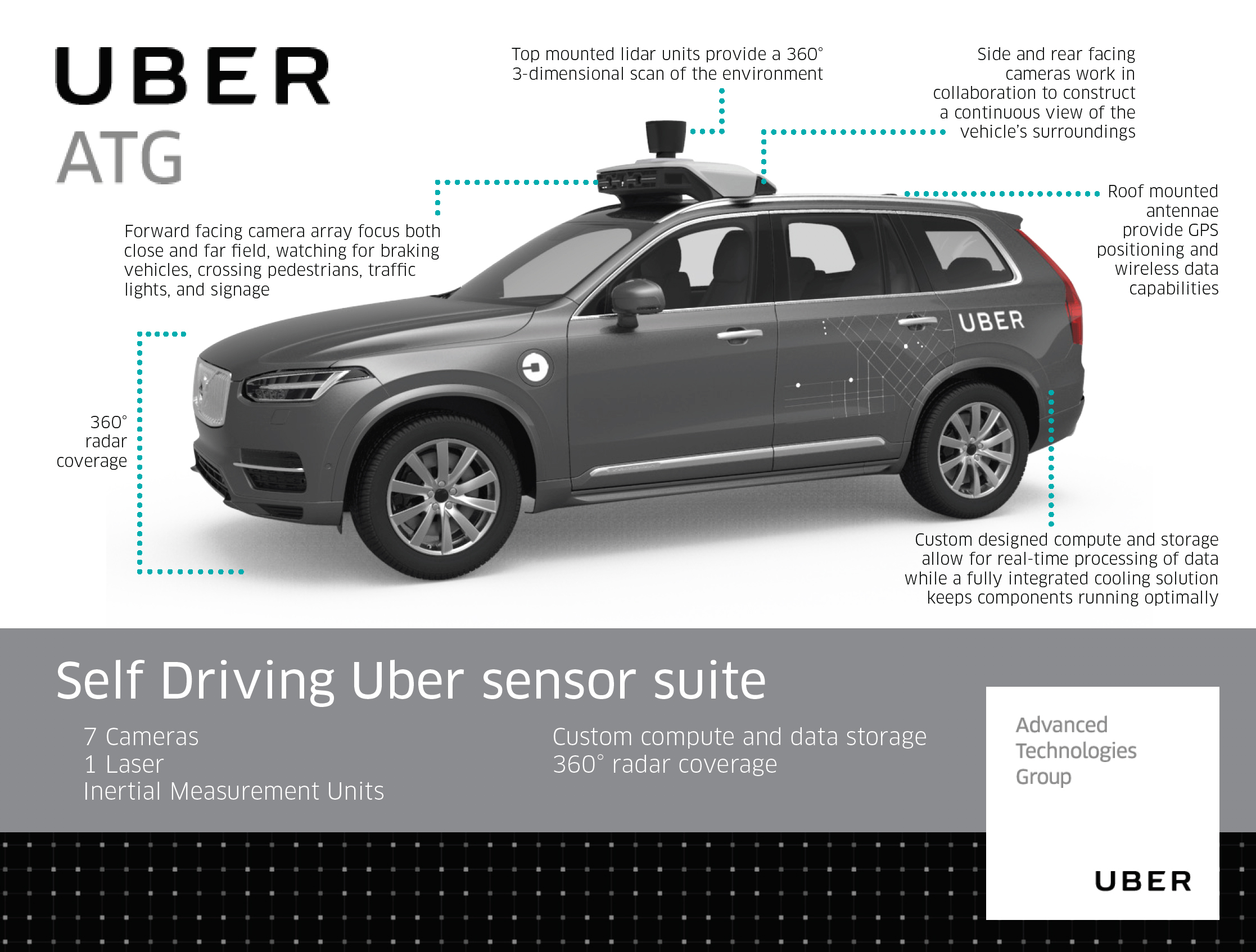 Top-mounted lidar. The bucket-shaped item on top of these cars is a
Top-mounted lidar. The bucket-shaped item on top of these cars is a 
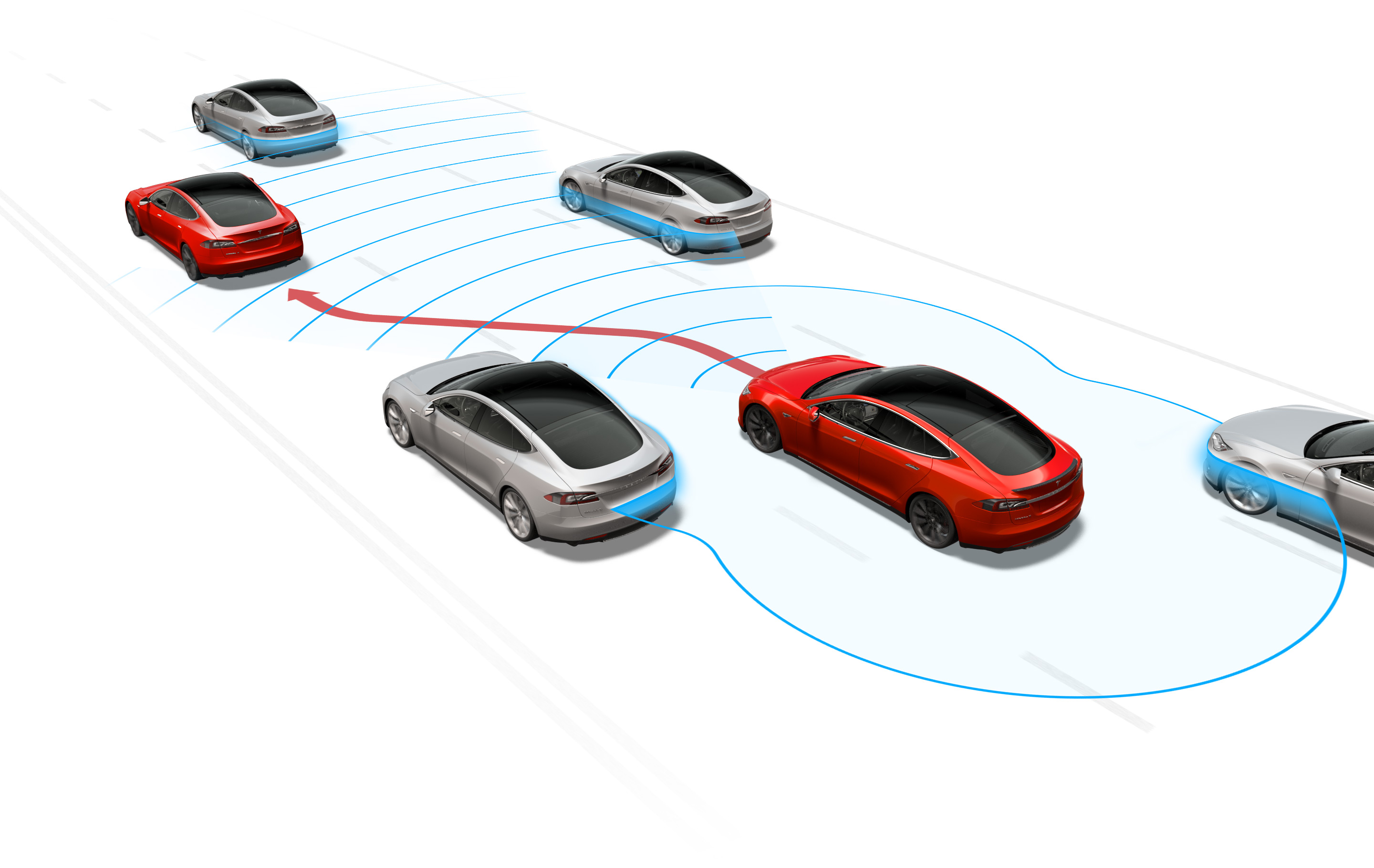
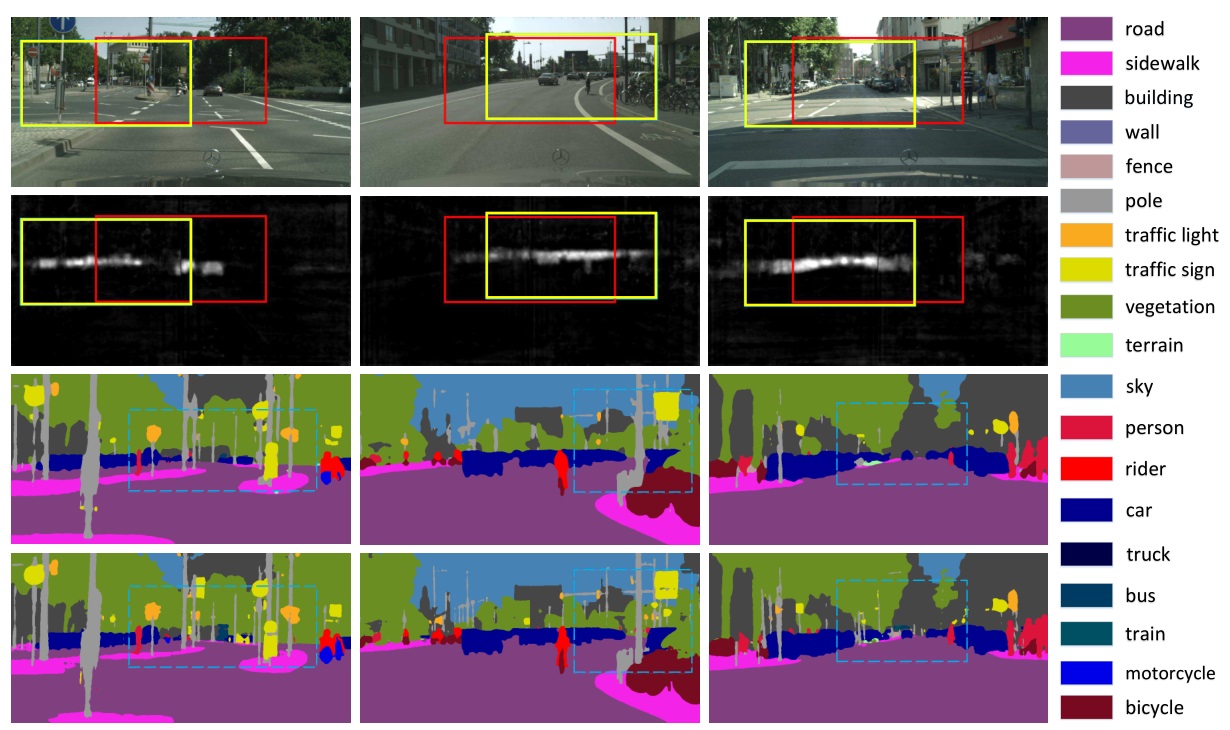 Detecting people is one of the most commonly attempted computer vision problems, and the algorithms that do it have gotten quite good. “Segmenting” an image, as it’s often called, generally also involves identifying things like signs, trees, sidewalks and more.
Detecting people is one of the most commonly attempted computer vision problems, and the algorithms that do it have gotten quite good. “Segmenting” an image, as it’s often called, generally also involves identifying things like signs, trees, sidewalks and more.
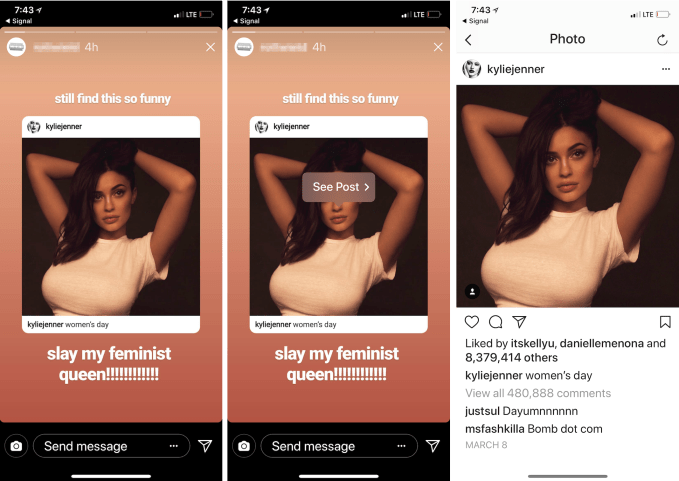
 Users who don’t want their posts to be “quote-Storied” can turn off the option in their settings, and only public posts can be reshared. Facebook says it doesn’t have details about a wider potential rollout beyond the small percentage of users currently with access. But given the popularity of
Users who don’t want their posts to be “quote-Storied” can turn off the option in their settings, and only public posts can be reshared. Facebook says it doesn’t have details about a wider potential rollout beyond the small percentage of users currently with access. But given the popularity of 