A team of researchers at Duo Security has unearthed a sophisticated botnet operating on Twitter — and being used to spread a cryptocurrency scam.
The botnet was discovered during the course of a wider research project to create and publish a methodology for identifying Twitter account automation — to help support further research into bots and how they operate.
The team used Twitter’s API and some standard data enrichment techniques to create a large data set of 88 million public Twitter accounts, comprising more than half a billion tweets. (Although they say they focused on the last 200 tweets per account for the study.)
They then used classic machine learning methods to train a bot classifier, and later applied other tried and tested data science techniques to map and analyze the structure of botnets they’d uncovered.
They’re open sourcing their documentation and data collection system in the hopes that other researchers will pick up the baton and run with it — such as, say, to do a follow up study focused on trying to ID good vs bad automation.
Their focus for their own classifier was on pure-play bots, rather than hybrid accounts which intentionally blend automation with some human interactions to make bots even harder to spot.
They also not look at sentiment for this study — but were rather fixed on addressing the core question of whether a Twitter account is automated or not.
They say it’s likely a few ‘cyborg’ hybrids crept into their data-set, such as customer service Twitter accounts which operate with a mix of automation and staff attention. But, again, they weren’t concerned specifically with attempting to identify the (even more slippery) bot-human-agent hybrids — such as those, for example, involved in state-backed efforts to fence political disinformation.
The study led them into some interesting analysis of botnet architectures — and their paper includes a case study on the cryptocurrency scam botnet they unearthed (which they say was comprised of at least 15,000 bots “but likely much more”), and which attempts to syphon money from unsuspecting users via malicious “giveaway” links…
‘Attempts’ being the correct tense because, despite reporting the findings of their research to Twitter, they say this crypto scam botnet is still functioning on its platform — by imitating otherwise legitimate Twitter accounts, including news organizations (such as the below example), and on a much smaller scale, hijacking verified accounts…
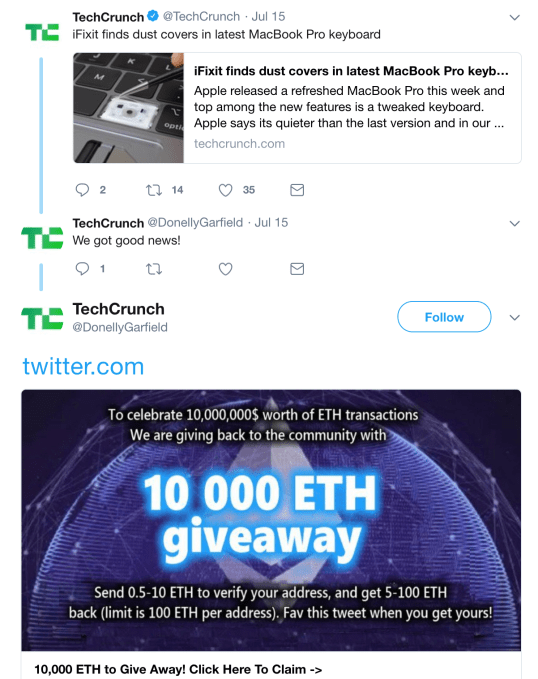
They even found Twitter recommending users follow other spam bots in the botnet under the “Who to follow” section in the sidebar. Ouch.
A Twitter spokeswoman would not answer our specific questions about its own experience and understanding of bots and botnets on its platform, so it’s not clear why it hasn’t been able to totally vanquish this crypto botnet yet. Although in a statement responding to the research, the company suggests this sort of spammy automation may be automatically detected and hidden by its anti-spam countermeasures (which would not be reflected in the data the Duo researchers had access to via the Twitter API).
Twitter said:
We are aware of this form of manipulation and are proactively implementing a number of detections to prevent these types of accounts from engaging with others in a deceptive manner. Spam and certain forms of automation are against Twitter’s rules. In many cases, spammy content is hidden on Twitter on the basis of automated detections. When spammy content is hidden on Twitter from areas like search and conversations, that may not affect its availability via the API. This means certain types of spam may be visible via Twitter’s API even if it is not visible on Twitter itself. Less than 5% of Twitter accounts are spam-related.
Twitter’s spokeswoman also make the (obvious) point that not all bots and automation is bad — pointing to a recent company blog which reiterates this, with the company highlighting the “delightful and fun experiences” served up by certain bots such as Pentametron, for example, a veteran automated creation which finds rhyming pairs of Tweets written in (accidental) iambic pentameter.
Certainly no one in their right mind would complain about a bot that offers automated homage to Shakespeare’s preferred meter. Even as no one in their right mind would not complain about the ongoing scourge of cryptocurrency scams on Twitter…
One thing is crystal clear: The tricky business of answering the ‘bot or not’ question is important — and increasingly so, given the weaponization of online disinformation. It may become a quest so politicized and imperative that platforms end up needing to display a ‘bot score’ alongside every account (Twitter’s spokeswoman did not respond when we asked if it might consider doing this).
While there are existing research methodologies and techniques for trying to determine Twitter automation, the team at Duo Security say they often felt frustrated by a lack of supporting data around them — and that that was one of their impetuses for carrying out the research.
“In some cases there was an incomplete story,” says data scientist Olabode Anise. “Where they didn’t really show how they got their data that they said that they used. And they maybe started with the conclusion — or most of the research talked about the conclusion and we wanted to give people the ability to take on this research themselves. So that’s why we’re open sourcing all of our methods and the tools. So that people can start from point ‘A’: First gathering the data; training a model; and then finding bots on Twitter’s platform locally.”
“We didn’t do anything fancy or investigative techniques,” he adds. “We were really outlying how we could do this at scale because we really think we’ve built one of the largest data sets associated with public twitter accounts.”
Anise says their classifier model was trained on data that formed part of a 2016 piece of research by researchers at the University of Southern California, along with some data from the crypto botnet they uncovered during their own digging in the data set of public tweets they created (because, as he puts it, it’s “a hallmark of automation” — so turns out cryptocurrency scams are good for something.)
In terms of determining the classifier’s accuracy, Anise says the “hard part” is the ongoing lack of data on how many bots are on Twitter’s platform.
You’d imagine (or, well, hope) Twitter knows — or can at least estimate that. But, either way, Twitter isn’t making that data-point public. Which means it’s difficult for researchers to verify the accuracy of their ‘bot or not’ models against public tweet data. Instead they have to cross-check classifiers against (smaller) data sets of labeled bot accounts. Ergo, accurately determining accuracy is another (bot-spotting related) problem.
Anise says their best model was ~98% “in terms of identifying different types of accounts correctly” when measured via a cross-check (i.e. so not checking against the full 88M data set because, as he puts it, “we don’t have a foolproof way of knowing if these accounts are bots or not”).
Still, the team sounds confident that their approach — using what they dub as “practical data science techniques” — can bear fruit to create a classifier that’s effective at finding Twitter bots.
“Basically we showed — and this was what we were really were trying to get across — is that some simple machine learning approaches that people who maybe watched a machine learning tutorial could follow and help identify bots successfully,” he adds.
One more small wrinkle: Bots that the model was trained on weren’t all forms of automation on Twitter’s platform. So he concedes that may also impact its accuracy. (Aka: “The model that you build is only going to be as good as the data that you have.” And, well, once again, the people with the best Twitter data all work at Twitter… )
The crypto botnet case study the team have included in their research paper is not just there for attracting attention: It’s intended to demonstrate how, using the tools and techniques they describe, other researchers can also progress from finding initial bots to pulling on threads, discovering and unraveling an entire botnet.
So they’ve put together a sort of ‘how to guide’ for Twitter botnet hunting.
The crypto botnet they analyze for the study, using social network mapping, is described in the paper as having a “unique three-tiered hierarchical structure”.
“Traditionally when Twitter botnets are found they typically follow a very flat structure where every bot in the botnet has the same job. They’re all going to spread a certain type of tweet or a certain type of spam. Usually you don’t see much co-ordination and segmentation in terms of the jobs that they have to do,” explains principal security engineer Jordan Wright.
“This botnet was unique because whenever we started mapping out the social connections between different bots — figuring out who did they follow and who follows them — we were able to enumerate a really clear structure showing bots that are connected in one particular way and an entire other cluster that were connected in a separate way.
“This is important because we see how the bot owners are changing their tactics in terms of how they were organizing these bots over time.”

They also discovered the spam tweets being published by the botnet were each being boosted by other bots in the botnet to amplify the overall spread of the cryptocurrency scam — Wright describes this as a process of “artificial inflation”, and says it works by the botnet owner making new bots whose sole job is to like or, later on, retweet the scammy tweets.
“The goal is to give them an artificial popularity so that if i’m the victim and I’m scrolling through Twitter and I come across these tweets I’m more likely to think that they’re legitimate based on how often they’ve been retweeted or how many times they’ve been liked,” he adds.
“Mapping out these connections between likes and, as well as the social network we have already gathered, really gives is us a multi layered botnet — that’s pretty unique, pretty sophisticated and very much organized where each bot had one, and really only one job, to do to try to help support the larger goal. That was unique to this botnet.”
Twitter has been making a bunch of changes recently intended to crack down on inauthentic platform activity which spammers have exploited to try to lend more authenticity and authority to their scams.
Clearly, though, there’s more work for Twitter to do.
“There are very practical reasons why we would consider it sophisticated,” adds Wright of the crypto botnet the team have turned into a case study. “It’s ongoing, it’s evolving and it’s changed its structure over time. And the structure that it has is hierarchical and organized.”
Anise and Wright will be presenting their Twitter botnet research on Wednesday, August 8 at the Black Hat conference.

 TechCrunch Startup Battlefield MENA 2018
TechCrunch Startup Battlefield MENA 2018