Nvidia, together with partners like IBM, HPE, Oracle, Databricks and others, is launching a new open-source platform for data science and machine learning today. Rapids, as the company is calling it, is all about making it easier for large businesses to use the power of GPUs to quickly analyze massive amounts of data and then use that to build machine learning models.
“Businesses are increasingly data-driven,” Nvidia’s VP of Accelerated Computing Ian Buck told me. “They sense the market and the environment and the behavior and operations of their business through the data they’ve collected. We’ve just come through a decade of big data and the output of that data is using analytics and AI. But most it is still using traditional machine learning to recognize complex patterns, detect changes and make predictions that directly impact their bottom line.”
The idea behind Rapids then is to work with the existing popular open-source libraries and platforms that data scientists use today and accelerate them using GPUs. Rapids integrates with these libraries to provide accelerated analytics, machine learning and — in the future — visualization.
Rapids is based on Python, Buck noted; it has interfaces that are similar to Pandas and Scikit, two very popular machine learning and data analysis libraries, and it’s based on Apache Arrow for in-memory database processing. It can scale from a single GPU to multiple notes and IBM notes that the platform can achieve improvements of up to 50x for some specific use cases when compared to running the same algorithms on CPUs (though that’s not all that surprising, given what we’ve seen from other GPU-accelerated workloads in the past).
Buck noted that Rapids is the result of a multi-year effort to develop a rich enough set of libraries and algorithms, get them running well on GPUs and build the relationships with the open-source projects involved.
“It’s designed to accelerate data science end-to-end,” Buck explained. “From the data prep to machine learning and for those who want to take the next step, deep learning. Through Arrow, Spark users can easily move data into the Rapids platform for acceleration.”
Indeed, Spark is surely going to be one of the major use cases here, so it’s no wonder that Databricks, the company founded by the team behind Spark, is one of the early partners.
“We have multiple ongoing projects to integrate Spark better with native accelerators, including Apache Arrow support and GPU scheduling with Project Hydrogen,” said Spark founder Matei Zaharia in today’s announcement. “We believe that RAPIDS is an exciting new opportunity to scale our customers’ data science and AI workloads.”
Nvidia is also working with Anaconda, BlazingDB, PyData, Quansight and scikit-learn, as well as Wes McKinney, the head of Ursa Labs and the creator of Apache Arrow and Pandas.
Another partner is IBM, which plans to bring Rapids support to many of its services and platforms, including its PowerAI tools for running data science and AI workloads on GPU-accelerated Power9 servers, IBM Watson Studio and Watson Machine Learning and the IBM Cloud with its GPU-enabled machines. “At IBM, we’re very interested in anything that enables higher performance, better business outcomes for data science and machine learning — and we think Nvidia has something very unique here,” Rob Thomas, the GM of IBM Analytics told me.
“The main benefit to the community is that through an entirely free and open-source set of libraries that are directly compatible with the existing algorithms and subroutines that their used to — they now get access to GPU-accelerated versions of them,” Buck said. He also stressed that Rapids isn’t trying to compete with existing machine learning solutions. “Part of the reason why Rapids is open source is so that you can easily incorporate those machine learning subroutines into their software and get the benefits of it.”

 Today, the Cloud Foundry foundation is launching two new Kubernetes-related projects that take the integration between the two to a new level. The first is
Today, the Cloud Foundry foundation is launching two new Kubernetes-related projects that take the integration between the two to a new level. The first is 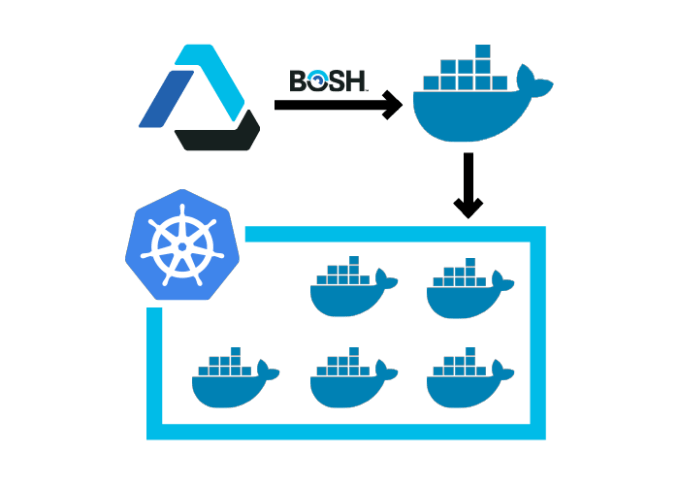 The second new project is
The second new project is