When Facebook’s Founder Mark Zuckerberg testified before House and Senate panels earlier this month, he explained how his company uses the data of millions of Americans. This particular set of hearings was urgent because our elected leaders have realized the power that lies in Facebook’s hidden trove of networked knowledge — its potential to violate privacy and the menace it poses to the integrity of our democratic institutions.
Facebook is a business that sells social connection, its algorithms are made for targeted advertising. The data that we users provide via friends, likes and shares makes their model lucrative. But connecting a person to a pair of shoes cannot be the same engagement algorithm that we use to build a cohesive democratic society. Watch any hearing on Capitol Hill.
It’s a durable, if old fashioned bridge between leaders and citizens. Informed deliberation could be a lot more compelling, but it can never compete on the same turf with funny GIFs and targeted videos. Algorithms optimized for commercial engagement do not protect public goods like democratic discourse. They are built for shareholders, not citizens. To the contrary, they can exploit and damage democracy’s most precious resource– civic trust.
One hundred cardboard cutouts of Facebook founder and CEO Mark Zuckerberg stand outside the US Capitol in Washington, DC, April 10, 2018. Advocacy group Avaaz is calling attention to what the groups says are hundreds of millions of fake accounts still spreading disinformation on Facebook. (Photo: SAUL LOEB/AFP/Getty Images)
Congress is the world’s most powerful representative assembly. Yet, like much of the US government, it does not have adequate 21st century technology knowledge, nor modern digital infrastructure for citizen input, much less interaction. Until we have an alternative that protects civic engagement data, the prevailing business models that rely on selling social connection will continue to be the equivalent of strip-mining democracy.
If we think we can use a corporate profit model for civics, we will get an increasingly coarse and volatile public life. Malevolence is cheap and conspiracy scales quickly. Junk news costs little compared to credible journalism. When clicks are the currency, the shortest path to a sale is vulgarity or shouting, which often stops inclusive participation altogether. It’s true that crowds are sometimes rowdy. But our democratic institutions are supposed to moderate this behavior and they are decades behind the private sector who themselves are struggling with online civility standards.
Another challenge is the scant institutional capacity our democracy has for coping with a digital world. For decades, Congress has purged its own expertise, especially on technology. The result is that it can’t match the White House when it comes to policy and it relies on the narrow perspectives of lobbyists more than ever. Congress does make available a great deal of information but–like a banana republic of data-– it lacks the resources to purchase the analysis products for its own workflow, or to create a competitive version for itself.
The longer we wait to build modern engagement capacity for our democracy, the more citizens will pay the price. In a political system awash with anonymous money, Congress is not building an integrity engine to audit the supply chain of data into policy. It is not optimizing the underused capacity of public serving knowledge already on Capitol Hill. It’s actually not far beyond hot lead type. Even the computer science interns still carry around 3 ring binders full of hard copy letters to sign.
Congress got a lot of attention for the Facebook hearings–much of it negative. But instead of focussing on the inadequate interrogation of Mark Zuckerberg, Americans should consider creative possibilities to enrich democratic discourse.
What if ⅓ of the committee hearing questions were open to colleagues with subject matter expertise from either party in either the House or the Senate? How about a preparatory “question challenge” to the verified citizens of the districts of the committee members? What about a curation platform to vet and incorporate audience feedback within the hearing itself? How about a stack exchange for the fresh questions so the rest of us watching from afar could rank them? And, why doesn’t Congress already have a computational intelligence capacity for every committee– one that could assist human staff with complex input in real time or asynchronously?
This future-dream is a steep hill, but it is not impossible. Until our governing institutions develop public-serving standards and systems, let’s follow the lead of truly modern democracies and put the civic engagement data of our nation where it will be safe and not for sale – in our collective hands. The urgent task for Congress and the rest of us is to restore civic trust. How about a series of follow-up hearings on who should be the information intermediaries for 21st century democracy?
Given the current international political climate, multi-lateral talks are another steep hill to climb. But we’ve looked abroad for common good norms in the past. We can start now by recognizing that open democratic standards are a modern source of power and influence. Iceland created a civic non profit to engage citizens and protect their data.
In an unfortunate step backward, the Facebook hearings returned us to the old familiar Russia vs. the West framework. But it is worth remembering how –in the last century– democracy won the Cold War because of off-shored norms.
Forty three years ago, 35 national leaders gathered in Finland to collaborate on reducing tensions with the eastern bloc, then dominated by the Soviet Union. The resultingHelsinki Accords championed Rule of Law and Human Rights. These western democratic norms became the guide posts of eastern Europe’s dissidents. In Czechloslovakia, the Charter 77 movement drew strength from exposing the hypocrisy of their government, a signatory to the Accords. The norms were ultimately successful in 1989 with the fall of the Berlin Wall.
Democratic societies require trusted connection in order to survive. They also need credible, capable institutions. If we Americans want to rebuild our national confidence, we’ll need a digital engagement system that optimizes for human dignity, not corporate dollars. The first step is for Congress–our most democratic institution– to fund its own digital capacity. Even then, it will need trusted, privacy protecting partners.
There is no IPO that monetizes engaged citizens, there’s just a society that sticks together enough to keep talking, even when a lot of people are fed up and angry. Once we decide to protect the public trust, we can succeed and even lead again. But to be cautiously hopeful andparaphrase Benjamin Franklin, let’s offshore our democracy’s civic data norms until we can keep them ourselves.
That’s not the only subscription coming up though. Now Facebook is considering adding an ad-free subscription option. These rumors have come and gone in the past, with no sign of change in the company’s resolute focus on advertising as its core business model. Post-Cambridge Analytica and post-GDPR though, it seems the company’s position is more malleable, and could be following the plan laid out by my colleague Josh Constine recently. He pegged the potential price at $11 a month, given the company’s revenue per user.
I’m an emphatic champion of subscription models, particularly in media. Subscriptions align incentives in a way that advertising can never do, while also avoiding the morass of privacy and ethics that plague ad targeting. Subscription revenues are also more reliable than ad dollars, making it easier to budget and improve operational efficiency for an organization.
Incentive alignment is one thing, and my wallet is another. All of these subscriptions are starting to add up. These days, my media subscriptions are hovering around $80 a month, and I don’t even have TV. Storage costs for Google, Apple, and Dropbox are another $13 a month. Cable and cell service are another $200 a month combined. Software subscriptions are probably about $20 a month (although so many are annualized its hard to keep track of them). Amazon Prime and a few others total in around $25 a month.
I’m frustrated with this hell. I’m frustrated that the web’s promise of instant and free access to the world’s information appears to be dying. I’m frustrated that subscription usually means just putting formerly free content behind a paywall. I’m frustrated that the price for subscriptions seems wildly high compared to the ad dollars that the fees substitute for. And I’m frustrated that subscription pricing rarely seems to account for other subscriptions I have, even when content libraries are similar.
Subscriptions can be a great tool, but everyone seems to be doing them wrong. We need to transform our thinking here if we are to move on from the manacles of the ad networks.
Before we dive in though, let’s be clear: the web needs a business model. We didn’t need paywalls on the early web because we focused on plain text from other users. Plain text is easier to produce, lowering the friction for people to contribute, and it’s also cheaper to store and transmit, lowering the cost of bandwidth.
Today’s consumers though have significantly higher standards than the original users of the web. Consumers want immersive experiences, well-designed pages with fonts, graphics, photos, and videos coming together into a compelling format. That “quality” costs enormous sums in engineering and design talent, not to mention massively increasing bandwidth and storage costs.
Take my colleague Connie Loizos’ article from yesterday reporting on a new venture fund. The text itself is about 3.5 kilobytes uncompressed, but the total payload of the page if nothing is cached is more than 10 MB, or more than 3000x the data usage of the actual text itself. This pattern has become so common that it has been called the website obesity crisis. Yet, all of our research shows people want high-definition images with their stories, instant loading of articles on the site, and interactivity. Those features have to be paid somehow, begetting us the advertising and subscription models we see today.
The other cost is content production itself. Volunteers just haven’t produced the information we are seeking. Wikipedia is an extraordinary resource, but its depth falters when we start looking for information about our local communities, or news, or individuals who aren’t famous. The reality is that information gathering is hard work, and in a capitalist system, we need to compensate people to do it. My colleagues and I are passionate about startups and technology, but we need to eat to publish.
While an open, free, and democratized web is ideal, these two challenges demonstrate that a business model had to be attached to make it function. Advertising is one such model, with massive privacy violations required to optimize it. The other approach is charging for access.
Unfortunately, subscription seems to be an area filled with product engineers and marketers led by brain-dead executives. The default choice of Bloomberg this week and so many other publications is to simply put formerly free content behind a paywall. No consumer wants to pay for something they formerly got for free, and yet we repeatedly see examples of subscriptions designed this way.
I don’t know when media started hiring IRS accountants, but subscriptions should be seen as an upgrade, not a tax. A subscription should provide new features, content, and capabilities that didn’t exist before while maintaining the former product that consumers have enjoyed for years.
Take MoviePass for instance. Consumers can continue to watch movies as they always have in the past, but now they have a new subscription option to watch potentially more movies for a set price. Among my friends, MoviePass has completely changed the way they think of films. Instead of just seeing one blockbuster every month, they are heading to an art house film because “we’ve essentially already paid for it, so why not try it?” The pricing is clearly too cheap, but that shouldn’t distract from a product that offered a completely new experience from a subscription.
The hell is even worse though. We not only get paywalls where none existed before, but the prices of those subscriptions are always vastly more expensive than consumers ever wanted. It’s not just Bloomberg and media — it’s software too. I used to write everything in Ulysses, a syncing Markdown editor for OS X and iOS. I paid $70 to buy the apps, but then the company switched to a $40 a year annual subscription, and as the dozens of angry reviews and comments illustrate, that price is vastly out of proportion from the cost of providing the software (which I might add, is entirely hosted on iCloud infrastructure).
For product marketers, the default mentality is to extract a lot of value from the 1% of readers or users that are going to convert to paid. Subscriptions are always positioned as all-or-nothing, with limited metering or tiering, to try to force the conversion. To my mind though, the question is not how to get 1% of readers to pay an exorbitant price, but how to get say 20% of your readers to pay you a cheaper price. It’s not about exclusion, but about participation.
One way we could fix that situation would be to allow subscriptions to combine together more cheaply. We are starting to see this too: Spotify, Hulu, and Scribd appear to be investigating a deal in which consumers can get a joint subscription from these services for a lower rate. Setapp is a set of more than one hundred OS X apps that come bundled for about $10 a month.
I’d love to see more of these partnerships, because they are much more fair to the consumer and ultimately allow smaller subscription companies to compete with the likes of Google, Amazon, Apple, and others. Cross-marketing lowers subscriber acquisition costs, and those savings should ultimately stream down to the consumer.
Subscription hell is real, but that doesn’t mean the business model is flawed. Rather, we need to completely transform our thinking around these models, including the marketing behind them and the features that they offer. We also need to consider consumers and their wallets more holistically, since no one buys a subscription in a vacuum. For too long, paywall playbooks have just been copied rather than innovated upon. It’s time for product leaders to step up and build a better future.
Last week at KubeCon and CloudNativeCon in Copenhagen, we saw an open source community coming together, full of vim and vigor and radiating positive energy as it recognized its growing clout in the enterprise world. This project, which came out of Google just a few years ago, has gained acceptance and popularity astonishingly rapidly — and that has raised both a sense of possibility and a boat load of questions.
At this year’s European version of the conference, the community seemed to be coming to grips with that rapid growth as large corporate organizations like Red Hat, IBM, Google, AWS and VMware all came together with developers and startups trying to figure out exactly what they had here with this new thing they found.
The project has been gaining acceptance as the defacto container orchestration tool, and as that happened, it was no longer about simply getting a project off the ground and proving that it could work in production. It now required a greater level of tooling and maturity that previously wasn’t necessary because it was simply too soon.
As this has happened, the various members who make up this growing group of users, need to figure out, mostly on the fly, how to make it all work when it is no longer just a couple of developers and a laptop. There are now big boy and big girl implementations and they require a new level of sophistication to make them work.
Against this backdrop, we saw a project that appeared to be at an inflection point. Much like a startup that realizes it actually achieved the product-market fit it had hypothesized, the Kubernetes community has to figure out how to take this to the next level — and that reality presents some serious challenges and enormous opportunities.
A community in transition
The Kubernetes project falls under the auspices of the Cloud Native Computing Foundation (or CNCF for short). Consider that at the opening keynote, CNCF director Dan Kohn was brimming with enthusiasm, proudly rattling off numbers to a packed audience, showing the enormous growth of the project.
Photo: Ron Miller
If you wanted proof of Kubernetes’ (and by extension cloud native computing’s) rapid ascension, consider that the attendance at KubeCon in Copenhagen last week numbered 4300 registered participants, triple the attendance in Berlin just last year.
The hotel and conference center were buzzing with conversation. Every corner and hallway, every bar stool in the hotel’s open lobby bar, at breakfast in the large breakfast room, by the many coffee machines scattered throughout the venue, and even throughout the city, people chatted, debated and discussed Kubernetes and the energy was palpable.
David Aronchick, who now runs the open source Kubeflow Kubernetes machine learning project at Google, was running Kubernetes in the early days (way back in 2015) and he was certainly surprised to see how big it has become in such a short time.
“I couldn’t have predicted it would be like this. I joined in January, 2015 and took on project management for Google Kubernetes. I was stunned at the pent up demand for this kind of thing,” he said.
Growing up
Yet there was great demand, and with each leap forward and each new level of maturity came a new set of problems to solve, which in turn has created opportunities for new services and startups to fill in the many gaps. As Aparna Sinha, who is the Kubernetes group product manager at Google, said in her conference keynote, enterprise companies want some level of certainty that earlier adopters were willing to forego to take a plunge into the new and exciting world of containers.
Photo: Cloud Native Computing Foundation
As she pointed out, for others to be pulled along and for this to truly reach another level of adoption, it’s going to require some enterprise-level features and that includes security, a higher level of application tooling and a better overall application development experience. All these types of features are coming, whether from Google or from the myriad of service providers who have popped up around the project to make it easier to build, deliver and manage Kubernetes applications.
Sinha says that one of the reasons the project has been able to take off as quickly as it has, is that its roots lie in a container orchestration tool called Borg, which the company has been using internally for years. While that evolved into what we know today as Kubernetes, it certainly required some significant repackaging to work outside of Google. Yet that early refinement at Google gave it an enormous head start over an average open source project — which could account for its meteoric rise.
“When you take something so well established and proven in a global environment like Google and put it out there, it’s not just like any open source project invented from scratch when there isn’t much known and things are being developed in real time,” she said.
For every action
One thing everyone seemed to recognize at KubeCon was that in spite of the head start and early successes, there remains much work to be done, many issues to resolve. The companies using it today mostly still fall under the early adopter moniker. This remains true even though there are some full blown enterprise implementations like CERN, the European physics organization, which has spun up 210 Kubernetes clusters or JD.com, the Chinese Internet shopping giant, which has 20K servers running Kubernetes with the largest cluster consisting of over 5000 servers. Still, it’s fair to say that most companies aren’t that far along yet.
Photo: Ron Miller
But the strength of an enthusiastic open source community like Kubernetes and cloud native computing in general, means that there are companies, some new and some established, trying to solve these problems, and the multitude of new ones that seem to pop up with each new milestone and each solved issue.
As Abbie Kearns, who runs another open source project, the Cloud Foundry Foundation, put it in her keynote, part of the beauty of open source is all those eyeballs on it to solve the scads of problems that are inevitably going to pop up as projects expand beyond their initial scope.
“Open source gives us the opportunity to do things we could never do on our own. Diversity of thought and participation is what makes open source so powerful and so innovative,” she said.
It’s worth noting that several speakers pointed out that diversity of thought also required actual diversity of membership to truly expand ideas to other ways of thinking and other life experiences. That too remains a challenge, as it does in technology and society at large.
In spite of this, Kubernetes has grown and developed rapidly, while benefiting from a community which so enthusiastically supports it. The challenge ahead is to take that early enthusiasm and translate it into more actual business use cases. That is the inflection point where the project finds itself, and the question is will it be able to take that next step toward broader adoption or reach a peak and fall back.
We were skeptical about The Rain, a new Danish series from Netflix. Not that the trailer was bad, exactly. It’s just hard to take a show with the tagline “Stay Dry. Stay Alive.” very seriously.
But here at the Original Content podcast, we don’t just judge shows by their trailers. No, we actually watched the first few episodes of The Rain, and we discovered a surprisingly compelling — even, at times, scary — thriller.
As the title implies, the danger in The Rain comes from rainfall, which has mysteriously been infected with a deadly virus. Our heroes, siblings Simone (played by Alba August) and Rasmus (Lucas Lynggaard Tønnesen) take shelter in a secret bunker, only to emerge years later into a dramatically more frightening world.
You can listen in the player below, subscribe using Apple Podcasts or find us in your podcast player of choice. If you like the show, please let us know by leaving a review on Apple. You also can send us feedback directly.
Personal privacy is a fairly new concept. Most people used to live in tight-knit communities, constantly enmeshed in each other’s lives. The notion that privacy is an important part of personal security is even newer, and often contested, while the need for public security — walls which must be guarded, doors which must be kept locked — is undisputed. Even anti-state anarchists concede the existence of violent enemies and monsters.
Rich people can afford their own high walls and closed doors. Privacy has long been a luxury, and it’s still often treated that way; a disposable asset, nice-to-have, not essential. Reinforcing that attitude is the fact that it’s surprisingly easy, even instinctive, for human beings to live in a small community — anything below Dunbar’s Number — with very little privacy. Even I, a card-carrying semi-misanthropic introvert, have done that for months at a stretch and found it unexpectedly, disconcertingly natural.
And so when technological security is treated as a trade-off between public security and privacy, as it almost always is these days, the primacy of the former is accepted. Consider the constant demands for “golden key” back doors so that governments can access encrypted phones which are “going dark.” Its opponents focus on the fact that such a system will inevitably be vulnerable to bad actors — hackers, stalkers, “evil maids.” Few dare suggest that, even if a perfect magical golden key with no vulnerabilities existed, one which could only be used by government officials within their official remit, the question of whether it should be implemented would still be morally complex.
Consider license plate readers that soon enough will probably track the locations of most cars in California in near-real-time with remarkable precision. Consider how the Golden State Killer was identified, by trawling through public genetic data to look for family matches; as FiveThirtyEight puts it, “you can’t opt out of sharing your data, even if you didn’t opt in” any more. Which would be basically fine, as long as we can guarantee hackers don’t get their hands on that data, right? Public security — catching criminals, preventing terror attacks — is far more important than personal privacy. Right?
Consider too corporate security, which, like public security, is inevitably assumed to be far more important than personal privacy. Until recently, Signal, the world’s premier private messaging app, used a technical trick known as “domain fronting,” on Google and Amazon web services, to provide access in countries which had tried to ban it — until this month, when Google disabled domain fronting and Amazon threatened termination of their AWS account, because the privacy of vulnerable populations is not important to them. Consider Facebook’s countless subtle assaults on personal privacy, in the name of connecting people, which happens to be how Facebook becomes ever stronger and more inescapable, while maintaining much stronger controls for its own employees and data.
But even strict corporate secrecy just reinforces the notion that privacy is a luxury for the rich and powerful, an inessential. It wouldn’t make that much difference if Amazon or Facebook or Google or even Apple were to open up their books and their roadmaps. Similarly, it won’t make that much difference if ordinary people have to give up their privacy in the name of public security, right? Living in communities where everyone knows one another’s business is natural, and arguably healthier than the disjoint dysfunction of, say, an apartment building whose dozens of inhabitants don’t even know each other’s names. Public security is essential; privacy is nice-to-have.
…Except.
…Except this dichotomy between “personal privacy” and “public security,” all too often promulgated by people who should know better, is completely false, a classic motte-and-bailey argument in bad faith. When we talk about “personal privacy” in the context of phone data, or license plate readers, or genetic data, or encrypted messaging, we’re not talking about anything even remotely like our instinctive human understanding of “privacy,” that of a luxury for the rich, inessential for people in healthy close-knit communities. Instead we’re talking about the collection and use of personal data at scale; governments and corporations accumulating massive amounts of highly personal information from billions of people.
This accumulation of data is, in and of itself, not a “personal privacy” issue, but a massive public security problem.
At least three problems, in fact. One is that the lack of privacy has a chilling effect on dissidence and original thought. Private spaces are the experimental petri dishes for societies. If you know your every move can be watched, and your every communication can be monitored, so private spaces effectively don’t exist, you’re much less likely to experiment with anything edgy or controversial; and in this era of cameras everywhere, facial recognition, gait recognition, license plate readers, Stingrays, etc., your every move can be watched.
If you don’t like the ethos of your tiny community, you can move to another one whose ethos you do like, but it’s a whole lot harder to change nation-states. Remember when marijuana and homosexuality were illegal in the West? (As they still are, in many places.) Would that have changed if ubiquitous surveillance and at-scale enforcement of those laws had been possible, back then? Are we so certain that all of our laws are perfect and just today, and that we will respond to new technologies by immediately regulating them with farsighted wisdom? I’m not. I’m anything but.
A second problem is that privacy eradication for the masses, coupled with privacy for the rich, will, as always, help to perpetuate status-quo laws / standards / establishments, and encourage parasitism, corruption, and crony capitalism. Cardinal Richelieu famously said, “If one would give me six lines written by the hand of the most honest man, I would find something in them to have him hanged.” Imagine how much easier it gets if the establishment has access to everything any dissident has ever said and done, while maintaining their own privacy. How long before “anti-terrorism” privacy eradication becomes “selective enforcement of unjust laws” becomes “de facto ‘oppo research’ unleashed on anyone who challenges the status quo”?
A third problem is that technology keeps getting better and better at manipulating the public based on their private data. Do you think ads are bad now? Once AIs start optimizing the advertising → behavior → data feedback loop, you may well like the ads you see, probably on a primal, mammalian, limbic level. Proponents argue that this is obviously better than disliking them. But the propaganda → behavior → data loop is no different from advertising → behavior → data, and no less subject to “optimization.”
When accumulated private data can be used to manipulate public opinion on a massive scale, privacy is no longer a personal luxury. When the rich establishment can use asymmetric privacy to discredit dissidents while remaining opaque themselves, privacy is no longer a personal luxury. When constant surveillance, or the threat thereof, systematically chills and dissuades people from experimenting with new ideas and expressing contentious thoughts, privacy is no longer a personal luxury. And that, I fear, is the world we may live in soon enough, if we don’t already.
Earlier today, the services marketplace Thumbtack held a small conference for 300 of its best gig economy workers at an event space in San Francisco.
For the nearly ten-year-old company the event was designed to introduce some new features and a redesign of its brand that had softly launched earlier in the week. On hand, in addition to the services professionals who’d paid their way from locations across the U.S. were the company’s top executives.
It’s the latest step in the long journey that Thumbtack took to become one of the last companies standing with a consumer facing marketplace for services.
Back in 2008, as the global financial crisis was only just beginning to tear at the fabric of the U.S. economy, entrepreneurs at companies like Thumbtack andTaskRabbit were already hard at work on potential patches.
This was the beginning of what’s now known as the gig economy. In addition to Thumbtack and TaskRabbit, young companies like Handy, Zaarly, and several others — all began by trying to build better marketplaces for buyers and sellers of services. Their timing, it turns out, was prescient.
In snowy Boston during the winter of 2008, Kevin Busque and his wife Leah were building RunMyErrand, the marketplace service that would become TaskRabbit, as a way to avoid schlepping through snow to pick up dog food .
Meanwhile, in San Francisco, Marco Zappacosta, a young entrepreneur whose parents were the founders of Logitech, and a crew of co-founders including were building Thumbtack, a professional services marketplace from a home office they shared.
As these entrepreneurs built their businesses in northern California (amid the early years of a technology renaissance fostered by patrons made rich from returns on investments in companies like Google and Salesforce.com), the rest of America was stumbling.
In the two years between 2008 and 2010 the unemployment rate in America doubled, rising from 5% to 10%. Professional services workers were hit especially hard as banks, insurance companies, realtors, contractors, developers and retailers all retrenched — laying off staff as the economy collapsed under the weight of terrible loans and a speculative real estate market.
Things weren’t easy for Thumbtack’s founders at the outset in the days before its $1.3 billion valuation and last hundred plus million dollar round of funding. “One of the things that really struck us about the team, was just how lean they were. At the time they were operating out of a house, they were still cooking meals together,” said Cyan Banister, one of the company’s earliest investors and a partner at the multi-billion dollar venture firm, Founders Fund.
“The only thing they really ever spent money on, was food… It was one of these things where they weren’t extravagant, they were extremely purposeful about every dollar that they spent,” Banister said. “They basically slept at work, and were your typical startup story of being under the couch. Every time I met with them, the story was, in the very early stages was about the same for the first couple years, which was, we’re scraping Craigslist, we’re starting to get some traction.”
The idea of powering a Craigslist replacement with more of a marketplace model was something that appealed to Thumbtack’s earliest investor and champion, the serial entrepreneur and angel investor Jason Calcanis.
Thumbtack chief executive Marco Zappacosta
“I remember like it was yesterday when Marco showed me Thumbtack and I looked at this and I said, ‘So, why are you building this?’ And he said, ‘Well, if you go on Craigslist, you know, it’s like a crap shoot. You post, you don’t know. You read a post… you know… you don’t know how good the person is. There’re no reviews.'” Calcanis said. “He had made a directory. It wasn’t the current workflow you see in the app — that came in year three I think. But for the first three years, he built a directory. And he showed me the directory pages where he had a photo of the person, the services provided, the bio.”
The first three years were spent developing a list of vendors that the company had verified with a mailing address, a license, and a certificate of insurance for people who needed some kind of service. Those three features were all Calcanis needed to validate the deal and pull the trigger on an initial investment.
“That’s when I figured out my personal thesis of angel investing,” Calcanis said.
“Some people are market based; some people want to invest in certain demographics or psychographics; immigrant kids or Stanford kids, whatever. Mine is just, ‘Can you make a really interesting product and are your decisions about that product considered?’ And when we discuss those decisions, do I feel like you’re the person who should build this product for the world And it’s just like there’s a big sign above Marco’s head that just says ‘Winner! Winner! Winner!'”
Indeed, it looks like Zappacosta and his company are now running what may be their victory lap in their tenth year as a private company. Thumbtack will be profitable by 2019 and has rolled out a host of new products in the last six months.
Their thesis, which flew in the face of the conventional wisdom of the day, was to build a product which offered listings of any service a potential customer could want in any geography across the U.S. Other companies like Handy and TaskRabbit focused on the home, but on Thumbtack (like any good community message board) users could see postings for anything from repairman to reiki lessons and magicians to musicians alongside the home repair services that now make up the bulk of its listings.
“It’s funny, we had business plans and documents that we wrote and if you look back, the vision that we outlined then, is very similar to the vision we have today. We honestly looked around and we said, ‘We want to solve a problem that impacts a huge number of people. The local services base is super inefficient. It’s really difficult for customers to find trustworthy, reliable people who are available for the right price,'” said Sander Daniels, a co-founder at the company.
“For pros, their number one concern is, ‘Where do I put money in my pocket next? How do I put food on the table for my family next?’ We said, ‘There is a real human problem here. If we can connect these people to technology and then, look around, there are these global marketplace for products: Amazon, Ebay, Alibaba, why can’t there be a global marketplace for services?’ It sounded crazy to say it at the time and it still sounds crazy to say, but that is what the dream was.”
Daniels acknowledges that the company changed the direction of its product, the ways it makes money, and pivoted to address issues as they arose, but the vision remained constant.
Meanwhile, other startups in the market have shifted their focus. Indeed as Handy has shifted to more of a professional services model rather than working directly with consumers and TaskRabbit has been acquired by Ikea, Thumbtack has doubled down on its independence and upgrading its marketplace with automation tools to make matching service providers with customers that much easier.
Thumbtack processes about $1 billion a year in business for its service providers in roughly 1,000 professional categories.
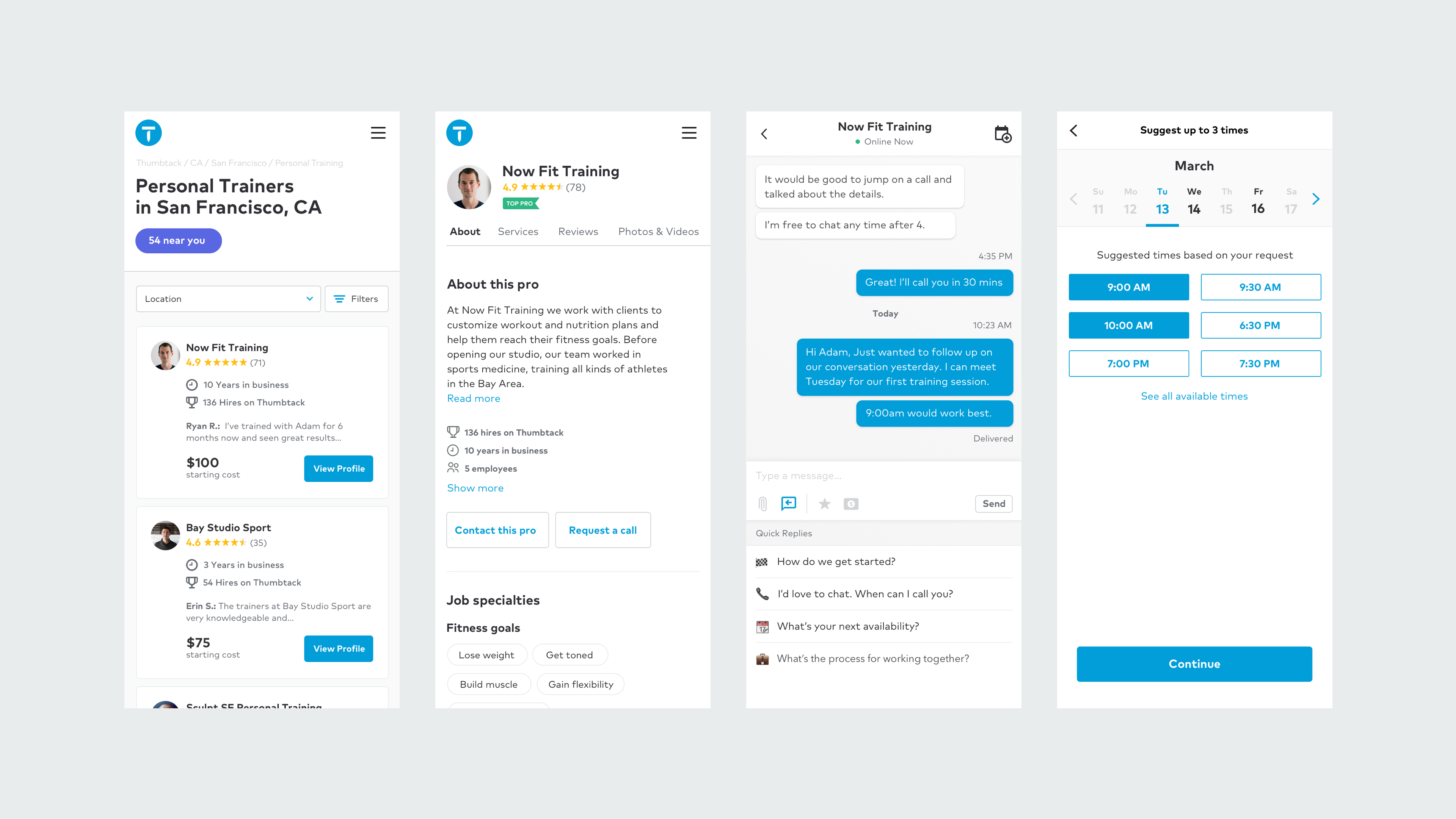
Now, the matching feature is getting an upgrade on the consumer side. Earlier this month the company unveiled Instant Results — a new look for its website and mobile app — that uses all of the data from its 200,000 services professionals to match with the 30 professionals that best correspond to a request for services. It’s among the highest number of professionals listed on any site, according to Zappacosta. The next largest competitor, Yelp, has around 115,000 listings a year. Thumbtack’s professionals are active in a 90 day period.
Filtering by price, location, tools and schedule, anyone in the U.S. can find a service professional for their needs. It’s the culmination of work processing nine years and 25 million requests for services from all of its different categories of jobs.
It’s a long way from the first version of Thumbtack, which had a “buy” tab and a “sell” tab; with the “buy” side to hire local services and the “sell” to offer them.
“From the very early days… the design was to iterate beyond the traditional model of business listing directors. In that, for the consumer to tell us what they were looking for and we would, then, find the right people to connect them to,” said Daniels. “That functionality, the request for quote functionality, was built in from v.1 of the product. If you tried to use it then, it wouldn’t work. There were no businesses on the platform to connect you with. I’m sure there were a million bugs, the UI and UX were a disaster, of course. That was the original version, what I remember of it at least.”
It may have been a disaster, but it was compelling enough to get the company its $1.2 million angel round — enough to barely develop the product. That million dollar investment had to last the company through the nuclear winter of America’s recession years, when venture capital — along with every other investment class — pulled back.
“We were pounding the pavement trying to find somebody to give us money for a Series A round,” Daniels said. “That was a very hard period of the company’s life when we almost went out of business, because nobody would give us money.”
That was a pre-revenue period for the company, which experimented with four revenue streams before settling on the one that worked the best. In the beginning the service was free, and it slowly transitioned to a commission model. Then, eventually, the company moved to a subscription model where service providers would pay the company a certain amount for leads generated off of Thumbtack.
“We weren’t able to close the loop,” Daniels said. “To make commissions work, you have to know who does the job, when, for how much. There are a few possible ways to collect all that information, but the best one, I think, is probably by hosting payments through your platform. We actually built payments into the platform in 2011 or 2012. We had significant transaction volume going through it, but we then decided to rip it out 18 months later, 24 months later, because, I think we had kind of abandoned the hope of making commissions work at that time.”
While Thumbtack was struggling to make its bones, Twitter, Facebook, and Pinterest were raking in cash. The founders thought that they could also access markets in the same way, but investors weren’t interested in a consumer facing business that required transactions — not advertising — to work. User generated content and social media were the rage, but aside from Uber and Lyft the jury was still out on the marketplace model.
“For our company that was not a Facebook or a Twitter or Pinterest, at that time, at least, that we needed revenue to show that we’re going to be able to monetize this,” Daniels said. “We had figured out a way to sign up pros at enormous scale and consumers were coming online, too. That was showing real promise. We said, ‘Man, we’re a hot ticket, we’re going to be able to raise real money.’ Then, for many reasons, our inexperience, our lack of revenue model, probably a bunch of stuff, people were reluctant to give us money.”
The company didn’t focus on revenue models until the fall of 2011, according to Daniels. Then after receiving rejection after rejection the company’s founders began to worry. “We’re like, ‘Oh, shit.’ November of 2009 we start running these tests, to start making money, because we might not be able to raise money here. We need to figure out how to raise cash to pay the bills, soon,” Daniels recalled.
The experience of almost running into the wall put the fear of god into the company. They managed to scrape out an investment from Javelin, but the founders were convinced that they needed to find the right revenue number to make the business work with or without a capital infusion. After a bunch of deliberations, they finally settled on $350,000 as the magic number to remain a going concern.
“That was the metric that we were shooting towards,” said Daniels. “It was during that period that we iterated aggressively through these revenue models, and, ultimately, landed on a paper quote. At the end of that period then Sequoia invested, and suddenly, pros supply and consumer demand and revenue model all came together and like, ‘Oh shit.'”
Finding the right business model was one thing that saved the company from withering on the vine, but another choice was the one that seemed the least logical — the idea that the company should focus on more than just home repairs and services.
The company’s home category had lots of competition with companies who had mastered the art of listing for services on Google and getting results. According to Daniels, the company couldn’t compete at all in the home categories initially.
“It turned out, randomly … we had no idea about this … there was not a similarly well developed or mature events industry,” Daniels said. “We outperformed in events. It was this strategic decision, too, that, on all these 1,000 categories, but it was random, that over the last five years we are the, if not the, certainly one of the leading events service providers in the country. It just happened to be that we … I don’t want to say stumbled into it … but we found these pockets that were less competitive and we could compete in and build a business on.”
The focus on geographical and services breadth — rather than looking at building a business in a single category or in a single geography meant that Zappacosta and company took longer to get their legs under them, but that they had a much wider stance and a much bigger base to tap as they began to grow.
“Because of naivete and this dreamy ambition that we’re going to do it all. It was really nothing more strategic or complicated than that,” said Daniels. “When we chose to go broad, we were wandering the wilderness. We had never done anything like this before.”
From the company’s perspective, there were two things that the outside world (and potential investors) didn’t grasp about its approach. The first was that a perfect product may have been more competitive in a single category, but a good enough product was better than the terrible user experiences that were then on the market. “You can build a big company on this good enough product, which you can then refine over the course of time to be greater and greater,” said Daniels.
The second misunderstanding is that the breadth of the company let it scale the product that being in one category would have never allowed Thumbtack to do. Cross selling and upselling from carpet cleaners to moving services to house cleaners to bounce house rentals for parties — allowed for more repeat use.
More repeat use meant more jobs for services employees at a time when unemployment was still running historically high. Even in 2011, unemployment remained stubbornly high. It wasn’t until 2013 that the jobless numbers began their steady decline.
There’s a question about whether these gig economy jobs can keep up with the changing times. Now, as unemployment has returned to its pre-recession levels, will people want to continue working in roles that don’t offer health insurance or retirement benefits? The answer seems to be “yes” as the Thumbtack platform continues to grow and Uber and Lyft show no signs of slowing down.
“At the time, and it still remains one of my biggest passions, I was interested in how software could create new meaningful ways of working,” said Banister of the Thumbtack deal. “That’s the criteria I was looking for, which is, does this shift how people find work? Because I do believe that we can create jobs and we can create new types of jobs that never existed before with the platforms that we have today.”
Machine learning may be the tool de jour for everything from particle physics to recreating the human voice, but it’s not exactly the easiest field to get into. Despite the complexities of video editing and sound design, we have UIs that let even a curious kid dabble in them — why not with machine learning? That’s the goal of Lobe, a startup and platform that genuinely seems to have made AI models as simple to put together as LEGO bricks.
I talked with Mike Matas, one of Lobe’s co-founders and the designer behind many a popular digital interface, about the platform and his motivations for creating it.
“There’s been a lot of situations where people have kind of thought about AI and have these cool ideas, but they can’t execute them,” he said. “So those ideas just like shed, unless you have access to an AI team.”
This happened to him, too, he explained.
“I started researching because I wanted to see if I could use it myself. And there’s this hard to break through veneer of words and frameworks and mathematics — but once you get through that the concepts are actually really intuitive. In fact even more intuitive than regular programming, because you’re teaching the machine like you teach a person.”
But like the hard shell of jargon, existing tools were also rough on the edges — powerful and functional, but much more like learning a development environment than playing around in Photoshop or Logic.
“You need to know how to piece these things together, there are lots of things you need to download. I’m one of those people who if I have to do a lot of work, download a bunch of frameworks, I just give up,” he said. “So as a UI designer I saw the opportunity to take something that’s really complicated and reframe it in a way that’s understandable.”
Lobe, which Matas created with his co-founders Markus Beissinger and Adam Menges, takes the concepts of machine learning, things like feature extraction and labeling, and puts them in a simple, intuitive visual interface. As demonstrated in a video tour of the platform, you can make an app that recognizes hand gestures and matches them to emoji without ever seeing a line of code, let alone writing one. All the relevant information is there, and you can drill down to the nitty gritty if you want, but you don’t have to. The ease and speed with which new applications can be designed and experimented with could open up the field to people who see the potential of the tools but lack the technical know-how.
He compared the situation to the early days of PCs, when computer scientists and engineers were the only ones who knew how to operate them. “They were the only people able to use them, so they were they only people able to come up with ideas about how to use them,” he said. But by the late ’80s, computers had been transformed into creative tools, largely because of improvements to the UI.
Matas expects a similar flood of applications, even beyond the many we’ve already seen, as the barrier to entry drops.
“People outside the data science community are going to think about how to apply this to their field,” he said, and unlike before, they’ll be able to create a working model themselves.
A raft of examples on the site show how a few simple modules can give rise to all kinds of interesting applications: reading lips, tracking positions, understanding gestures, generating realistic flower petals. Why not? You need data to feed the system, of course, but doing something novel with it is no longer the hard part.
And in keeping with the machine learning community’s commitment to openness and sharing, Lobe models aren’t some proprietary thing you can only operate on the site or via the API. “Architecturally we’re built on top of open standards like Tensorflow,” Matas said. Do the training on Lobe, test it and tweak it on Lobe, then compile it down to whatever platform you want and take it to go.
Right now the site is in closed beta. “We’ve been overwhelmed with responses, so clearly it’s resonating with people,” Matas said. “We’re going to slowly let people in, it’s going to start pretty small. I hope we’re not getting ahead of ourselves.”
Another big development in the personal data misuse saga attached to the controversialTrump campaign-linked UK-based political consultancy, Cambridge Analytica — which could lead to fresh light being shed on how the company and its multiple affiliates acquired and processed US citizens’ personal data to build profiles on millions of voters for political targeting purposes.
The UK’s data watchdog, the ICO, has today announced that it’s served an enforcement notice on Cambridge Analytica affiliate SCL Elections, under the UK’s 1998 Data Protection Act.
The company has been ordered to give up all the data it holds on one US academic within 30 days — with the ICO warning that: “Failure to do so is a criminal offence, punishable in the courts by an unlimited fine.”
The notice follows a subject access request (SAR) filed in January last year by US-based academic, David Carroll after he became suspicious about how the company was able to build psychographic profiles of US voters. And while Carroll is not a UK citizen, he discovered his personal data had been processed in the UK — so decided to bring a test case by requesting his personal data under UK law.
Carroll’s complaint, and the ICO’s decision to issue an enforcement notice in support of it, looks to have paved the way for millions of US voters to also ask Cambridge Analytica for their data (the company claimed to have up to 7,000 data points on the entire US electorate, circa 240M people — so just imagine the class action that could be filed here… ).
The Guardian reports that Cambridge Analytica had tried to dismiss Carroll’s argument by claiming he had no more rights “than a member of the Taliban sitting in a cave in the remotest corner of Afghanistan”. The ICO clearly disagrees.
Important development. @ICOnews agrees with our complaint and orders full disclosure to @profcarroll following findings of non-cooperation by Cambridge Analytica / SCL. We look forward to full disclosure within 30 days. Decision here: https://t.co/X5g1FY95j0https://t.co/ZsonQhPsKQ
Cambridge Analytica/SCL Group responded to Carroll’s original SAR in March 2017 but he was unimpressed by the partial data they sent him — which ranked his interests on a selection of topics (including gun rights, immigration, healthcare, education and the environment) yet did not explain how the scores had been calculated.
It also listed his likely partisanship and propensity to vote in the 2016 US election — again without explaining how those predictions had been generated.
So Carroll complained to the UK’s data watchdog in September 2017 — which began sending its own letters to CA/SCL, leading to further unsatisfactory responses.
“The company’s reply refused to address the ICO’s questions and incorrectly stated Prof Caroll had no legal entitlement to it because he wasn’t a UK citizen or based in this country. The ICO reiterated this was not legally correct in a letter to SCL the following month,” the ICO writes today. “In November 2017, the company replied, denying that the ICO had any jurisdiction or that Prof Carroll was legally entitled to his data, adding that SCL did “.. not expect to be further harassed with this sort of correspondence”.”
In a strongly worded statement, information commissioner Elizabeth Denham further adds:
The company has consistently refused to co-operate with our investigation into this case and has refused to answer our specific enquiries in relation to the complainant’s personal data — what they had, where they got it from and on what legal basis they held it.
The right to request personal data that an organisation holds about you is a cornerstone right in data protection law and it is important that Professor Carroll, and other members of the public, understand what personal data Cambridge Analytica held and how they analysed it.
We are aware of recent media reports concerning Cambridge Analytica’s future but whether or not the people behind the company decide to fold their operation, a continued refusal to engage with the ICO will potentially breach an Enforcement Notice and that then becomes a criminal matter.
Since mid-March this year, Cambridge Analytica’s name (along with the names of various affiliates) has been all over headlines relating to a major Facebook data misuse scandal, after press reports revealed in granular detail how an app developer had used the social media’s platform’s 2014 API structure to extract and process large amounts of users’ personal data, passing psychometrically modeled scores on US voters to Cambridge Analytica for political targeting.
But Carroll’s curiosity about what data Cambridge Analytica might hold about him predates the scandal blowing up last month. Although journalists had actually raised questions about the company as far back as December 2015 — when the Guardian reported that the company was working for the Ted Cruz campaign, using detailed psychological profiles of voters derived from tens of millions of Facebook users’ data.
Carroll, who has studied the Internet ad tech industry as part of his academic work, reckons Facebook is not the sole source of the data in this case, telling the Guardian he expects to find a whole host of other companies are also implicated in this murky data economy where people’s personal information is quietly traded and passed around for highly charged political purposes — bankrolled by billionaires.
“I think we’re going to find that this goes way beyond Facebook and that all sorts of things are being inferred about us and then used for political purposes,” he told the newspaper.
Under mounting political, legal and public pressure, Cambridge Analytica claimed to be shutting down this week — but the move appears more like a rebranding exercise, as parent entity, SCL Group, maintains a sprawling network of companies and linked entities. (Such as one called Emerdata, which was founded in mid-2017 and is listed at the same address as SCL Elections, and has many of the same investors and management as Cambridge Analytica… But presumably hasn’t yet been barred from social media giants’ ad platforms, as its predecessor has.)
Closing one of the entities embroiled in the scandal could also be a tactic to impede ongoing investigations, such as the one by the ICO — as Denham’s statement alludes, by warning that any breach of the enforcement notice could lead to criminal proceedings being brought against the owners and operators of Cambridge Analytica’s parent entity.
In March ICO officials obtained a warrant to enter and search Cambridge Analytica’s London offices, removing documents and computers for examination as part of a wider, year-long investigation into the use of personal data and analytics by political campaigns, parties, social media companies and other commercial actors. And last month the watchdog said 30 organizations — including Facebook — were now part of that investigation.
The Guardian also reports that the ICO has suggested to Cambridge Analytica that if it has difficulties complying with the enforcement notice it should hand over passwords for the servers seized during the March raid on its London office – raising questions about how much data the watchdog has been able to retrieve from the seized servers.
SCL Group’s website contains no obvious contact details beyond a company LinkedIn profile — a link which appears to be defunct. But we reached out to SCL Group’s CEO Nigel Oakes, who has maintained a public LinkedIn presence, to ask if he has any response to the ICO enforcement notice.
Meanwhile Cambridge Analytica continues to use its public Twitter account to distribute a stream of rebuttals and alternative ‘facts’.
Why has San Francisco’s startup scene generated so many hugely valuable companies over the past decade?
That’s the question we asked over the past few weeks while analyzing San Francisco startup funding, exit, and unicorn creation data. After all, it’s not as if founders of Uber, Airbnb, Lyft, Dropbox and Twitter had to get office space within a couple of miles of each other.
We hadn’t thought our data-centric approach would yield a clear recipe for success. San Francisco private and newly public unicorns are a diverse bunch, numbering more than 30, in areas ranging from ridesharing to online lending. Surely the path to billion-plus valuations would be equally varied.
But surprisingly, many of their secrets to success seem formulaic. The most valuable San Francisco companies to arise in the era of the smartphone have a number of shared traits, including a willingness and ability to post massive, sustained losses; high-powered investors; and a preponderance of easy-to-explain business models.
No, it’s not a recipe that’s likely replicable without talent, drive, connections and timing. But if you’ve got those ingredients, following the principles below might provide a good shot at unicorn status.
First you conquer, then you earn
Losing money is not a bug. It’s a feature.
First, lose money until you’ve left your rivals in the dust. This is the most important rule. It is the collective glue that holds the narratives of San Francisco startup success stories together. And while companies in other places have thrived with the same practice, arguably San Franciscans do it best.
It’s no secret that a majority of the most valuable internet and technology companies citywide lose gobs of money or post tiny profits relative to valuations. Uber, called the world’s most valuable startup, reportedly lost $4.5 billion last year. Dropbox lost more than $100 million after losing more than $200 million the year before and more than $300 million the year before that. Even Airbnb, whose model of taking a share of homestay revenues sounds like an easy recipe for returns, took nine years to post its first annual profit.
Not making money can be the ultimate competitive advantage, if you can afford it.
Industry stalwarts lose money, too. Salesforce, with a market cap of $88 billion, has posted losses for the vast majority of its operating history. Square, valued at nearly $20 billion, has never been profitable on a GAAP basis. DocuSign, the 15-year-old newly public company that dominates the e-signature space, lost more than $50 million in its last fiscal year (and more than $100 million in each of the two preceding years). Of course, these companies, like their unicorn brethren, invest heavily in growing revenues, attracting investors who value this approach.
We could go on. But the basic takeaway is this: Losing money is not a bug. It’s a feature. One might even argue that entrepreneurs in metro areas with a more fiscally restrained investment culture are missing out.
What’s also noteworthy is the propensity of so many city startups to wreak havoc on existing, profitable industries without generating big profits themselves. Craigslist, a San Francisco nonprofit, may have started the trend in the 1990s by blowing up the newspaper classified business. Today, Uber and Lyft have decimated the value of taxi medallions.
Not making money can be the ultimate competitive advantage, if you can afford it, as it prevents others from entering the space or catching up as your startup gobbles up greater and greater market share. Then, when rivals are out of the picture, it’s possible to raise prices and start focusing on operating in the black.
Raise money from investors who’ve done this before
You can’t lose money on your own. And you can’t lose any old money, either. To succeed as a San Francisco unicorn, it helps to lose money provided by one of a short list of prestigious investors who have previously backed valuable, unprofitable Northern California startups.
It’s not a mysterious list. Most of the names are well-known venture and seed investors who’ve been actively investing in local startups for many years and commonly feature on rankings like the Midas List. We’ve put together a few names here.
You might wonder why it’s so much better to lose money provided by Sequoia Capital than, say, a lower-profile but still wealthy investor. We could speculate that the following factors are at play: a firm’s reputation for selecting winning startups, a willingness of later investors to follow these VCs at higher valuations and these firms’ skill in shepherding portfolio companies through rapid growth cycles to an eventual exit.
Whatever the exact connection, the data speaks for itself. The vast majority of San Francisco’s most valuable private and recently public internet and technology companies have backing from investors on the short list, commonly beginning with early-stage rounds.
Pick a business model that relatives understand
Generally speaking, you don’t need to know a lot about semiconductor technology or networking infrastructure to explain what a high-valuation San Francisco company does. Instead, it’s more along the lines of: “They have an app for getting rides from strangers,” or “They have an app for renting rooms in your house to strangers.” It may sound strange at first, but pretty soon it’s something everyone seems to be doing.
It’s not a recipe that’s likely replicable without talent, drive, connections and timing.
A list of 32 San Francisco-based unicorns and near-unicorns is populated mostly with companies that have widely understood brands, including Pinterest, Instacart and Slack, along with Uber, Lyft and Airbnb. While there are some lesser-known enterprise software names, they’re not among the largest investment recipients.
Part of the consumer-facing, high brand recognition qualities of San Francisco startups may be tied to the decision to locate in an urban center. If you were planning to manufacture semiconductor components, for instance, you would probably set up headquarters in a less space-constrained suburban setting.
Reading between the lines of red ink
While it can be frustrating to watch a company lurch from quarter to quarter without a profit in sight, there is ample evidence the approach can be wildly successful over time.
Seattle’s Amazon is probably the poster child for this strategy. Jeff Bezos, recently declared the world’s richest man, led the company for more than a decade before reporting the first annual profit.
These days, San Francisco seems to be ground central for this company-building technique. While it’s certainly not necessary to locate here, it does seem to be the single urban location most closely associated with massively scalable, money-losing consumer-facing startups.
Perhaps it’s just one of those things that after a while becomes status quo. If you want to be a movie star, you go to Hollywood. And if you want to make it on Wall Street, you go to Wall Street. Likewise, if you want to make it by launching an industry-altering business with a good shot at a multi-billion-dollar valuation, all while losing eye-popping sums of money, then you go to San Francisco.






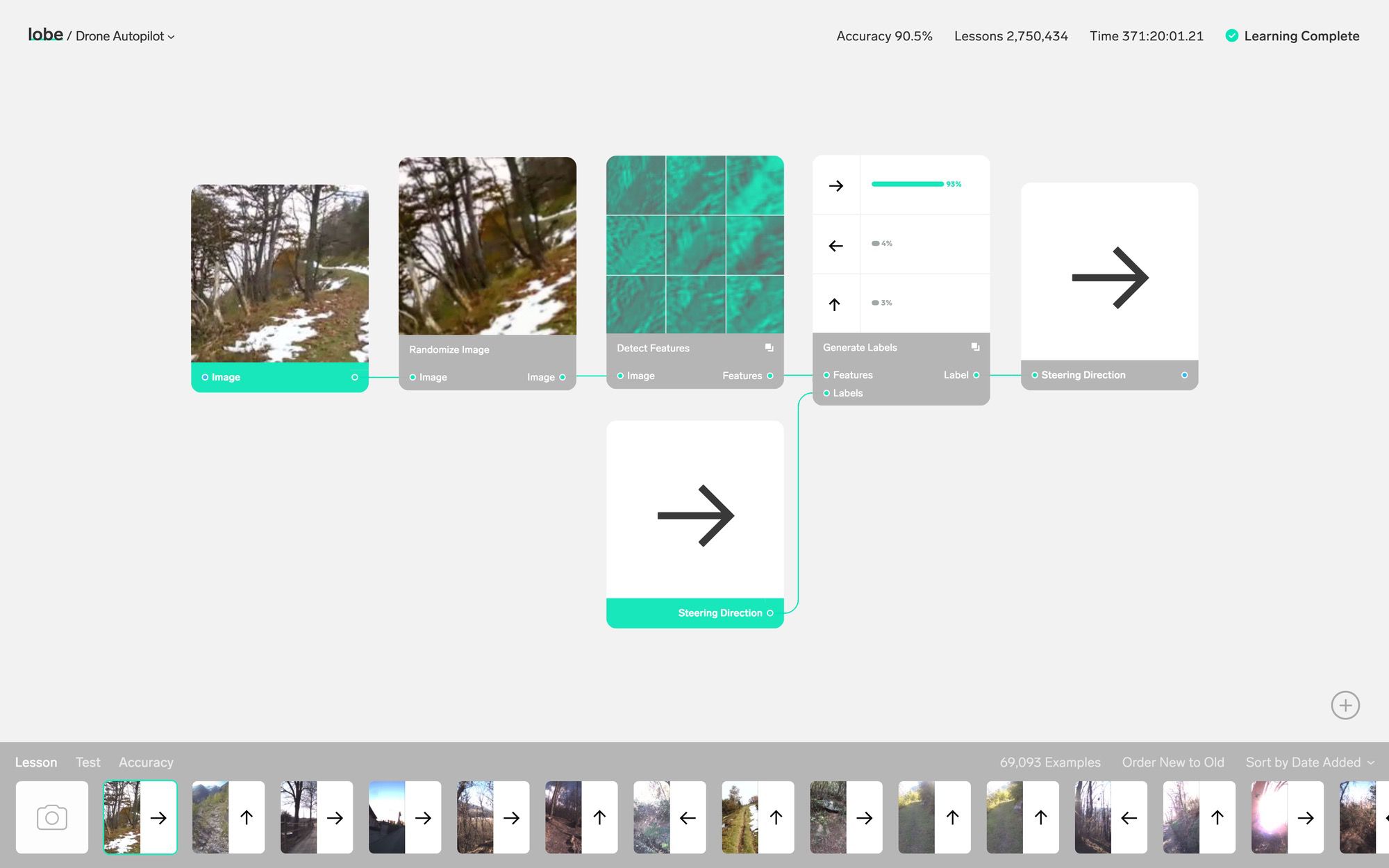 A raft of examples on the site show how a few simple modules can give rise to all kinds of interesting applications: reading lips, tracking positions, understanding gestures, generating realistic flower petals. Why not? You need data to feed the system, of course, but doing something novel with it is no longer the hard part.
A raft of examples on the site show how a few simple modules can give rise to all kinds of interesting applications: reading lips, tracking positions, understanding gestures, generating realistic flower petals. Why not? You need data to feed the system, of course, but doing something novel with it is no longer the hard part.