Make no mistake: Fresh battle lines are being drawn in the clash between data-mining tech giants and Internet users over people’s right to control their personal information and protect their privacy.
An update to European Union data protection rules next month — called the General Data Protection Regulation — is the catalyst for this next chapter in the global story of tech vs privacy.
A fairytale ending would remove that ugly ‘vs’ and replace it with an enlightened ‘+’. But there’s no doubt it will be a battle to get there — requiring legal challenges and fresh case law to be set down — as an old guard of dominant tech platforms marshal their extensive resources to try to hold onto the power and wealth gained through years of riding roughshod over data protection law.
Payback is coming though. Balance is being reset. And the implications of not regulating what tech giants can do with people’s data has arguably never been clearer.
The exciting opportunity for startups is to skate to where the puck is going — by thinking beyond exploitative legacy business models that amount to embarrassing blackboxes whose CEOs dare not publicly admit what the systems really do — and come up with new ways of operating and monetizing services that don’t rely on selling the lie that people don’t care about privacy.
More than just small print
Right now the EU’s General Data Protection Regulation can take credit for a whole lot of spilt ink as tech industry small print is reworded en masse. Did you just receive a T&C update notification about a company’s digital service? Chances are it’s related to the incoming standard.
The regulation is generally intended to strengthen Internet users’ control over their personal information, as we’ve explained before. But its focus on transparency — making sure people know how and why data will flow if they choose to click ‘I agree’ — combined with supersized fines for major data violations represents something of an existential threat to ad tech processes that rely on pervasive background harvesting of users’ personal data to be siphoned biofuel for their vast, proprietary microtargeting engines.
This is why Facebook is not going gentle into a data processing goodnight.
Indeed, it’s seizing on GDPR as a PR opportunity — shamelessly stamping its brand on the regulatory changes it lobbied so hard against, including by taking out full page print ads in newspapers…
This is of course another high gloss plank in the company’s PR strategy to try to convince users to trust it — and thus to keep giving it their data. Because — and only because — GDPR gives consumers more opportunity to lock down access to their information and close the shutters against countless prying eyes.
But the pressing question for Facebook — and one that will also test the mettle of the new data protection standard — is whether or not the company is doing enough to comply with the new rules.
One important point re: Facebook and GDPR is that the standard applies globally, i.e. for all Facebook users whose data is processed by its international entity, Facebook Ireland (and thus within the EU); but not necessarily universally — with Facebook users in North America not legally falling under the scope of the regulation.
Users in North America will only benefit if Facebook chooses to apply the same standard everywhere. (And on that point the company has stayed exceedingly fuzzy.)
It has claimed it won’t give US and Canadian users second tier status vs the rest of the world where their privacy is concerned — saying they’re getting the same “settings and controls” — but unless or until US lawmakers spill some ink of their own there’s nothing but an embarrassing PR message to regulate what Facebook chooses to do with Americans’ data. It’s the data protection principles, stupid.
Zuckerberg was asked by US lawmakers last week what kind of regulation he would and wouldn’t like to see laid upon Internet companies — and he made a point of arguing for privacy carve outs to avoid falling behind, of all things, competitors in China.
Which is an incredibly chilling response when you consider how few rights — including human rights — Chinese citizens have. And how data-mining digital technologies are being systematically used to expand Chinese state surveillance and control.
The ugly underlying truth of Facebook’s business is that it also relies on surveillance to function. People’s lives are its product.
That’s why Zuckerberg couldn’t tell US lawmakers to hurry up and draft their own GDPR. He’s the CEO saddled with trying to sell an anti-privacy, anti-transparency position — just as policymakers are waking up to what that really means.
Plus ça change?
Facebook has announced a series of updates to its policies and platform in recent months, which it’s said are coming to all users (albeit in ‘phases’). The problem is that most of what it’s proposing to achieve GDPR compliance is simply not adequate.
Coincidentally many of these changes have been announced amid a major data mishandling scandal for Facebook, in which it’s been revealed that data on up to 87M users was passed to a political consultancy without their knowledge or consent.
It’s this scandal that led Zuckerberg to be perched on a booster cushion in full public view for two days last week, dodging awkward questions from US lawmakers about how his advertising business functions.
He could not tell Congress there wouldn’t be other such data misuse skeletons in its closet. Indeed the company has said it expects it will uncover additional leaks as it conducts a historical audit of apps on its platform that had access to “a large amount of data”. (How large is large, one wonders… )
But whether Facebook’s business having enabled — in just one example — the clandestine psychological profiling of millions of Americans for political campaign purposes ends up being the final, final straw that catalyzes US lawmakers to agree their own version of GDPR is still tbc.
Any new law will certainly take time to formulate and pass. In the meanwhile GDPR is it.
The most substantive GDPR-related change announced by Facebook to date is the shuttering of a feature called Partner Categories — in which it allowed the linking of its own information holdings on people with data held by external brokers, including (for example) information about people’s offline activities.
Evidently finding a way to close down the legal liabilities and/or engineer consent from users to that degree of murky privacy intrusion — involving pools of aggregated personal data gathered by goodness knows who, how, where or when — was a bridge too far for the company’s army of legal and policy staffers.
Other notable changes it has so far made public include consolidating settings onto a single screen vs the confusing nightmare Facebook has historically required users to navigate just to control what’s going on with their data (remember the company got a 2011 FTC sanction for “deceptive” privacy practices); rewording its T&Cs to make it more clear what information it’s collecting for what specific purpose; and — most recently — revealing a new consent review process whereby it will be asking all users (starting with EU users) whether they consent to specific uses of their data (such as processing for facial recognition purposes).
As my TC colleague Josh Constine wrote earlier in a critical post dissecting the flaws of Facebook’s approach to consent review, the company is — at very least — not complying with the spirit of GDPR’s law.
Indeed, Facebook appears pathologically incapable of abandoning its long-standing modus operandi of socially engineering consent from users (doubtless fed via its own self-reinforced A/B testing ad expertise). “It feels obviously designed to get users to breeze through it by offering no resistance to continue, but friction if you want to make changes,” was his summary of the process.
But, as we’ve pointed out before, concealment is not consent.
To get into a few specifics, pre-ticked boxes — which is essentially what Facebook is deploying here, with a big blue “accept and continue” button designed to grab your attention as it’s juxtaposed against an anemic “manage data settings” option (which if you even manage to see it and read it sounds like a lot of tedious hard work) — aren’t going to constitute valid consent under GDPR.
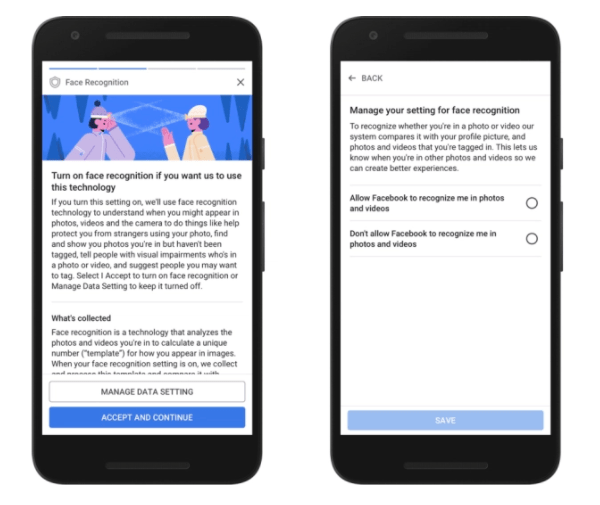
Nor is this what ‘privacy by default’ looks like — another staple principle of the regulation. On the contrary, Facebook is pushing people to do the opposite: Give it more of their personal information — and fuzzing why it’s asking by bundling a range of usage intentions.
The company is risking a lot here.
In simple terms, seeking consent from users in a way that’s not fair because it’s manipulative means consent is not being freely given. Under GDPR, it won’t be consent at all. So Facebook appears to be seeing how close to the wind it can fly to test how regulators will respond.
Safe to say, EU lawmakers and NGOs are watching.
“Yes, they will be taken to court”
“Consent should not be regarded as freely given if the data subject has no genuine or free choice or is unable to refuse or withdraw consent without detriment,” runs one key portion of GDPR.
Now compare that with: “People can choose to not be on Facebook if they want” — which was Facebook’s deputy chief privacy officer, Rob Sherman’s, paper-thin defense to reporters for the lack of an overall opt out for users to its targeted advertising.
Data protection experts who TechCrunch spoke to suggest Facebook is failing to comply with, not just the spirit, but the letter of the law here. Some were exceeding blunt on this point.
“I am less impressed,” said law professor Mireille Hildebrandt discussing how Facebook is railroading users into consenting to its targeted advertising. “It seems they have announced that they will still require consent for targeted advertising and refuse the service if one does not agree. This violates [GDPR] art. 7.4 jo recital 43. So, yes, they will be taken to court.”
“Zuckerberg appears to view the combination of signing up to T&Cs and setting privacy options as ‘consent’,” adds cyber security professor Eerke Boiten. “I doubt this is explicit or granular enough for the personal data processing that FB do. The default settings for the privacy settings certainly do not currently provide for ‘privacy by default’ (GDPR Art 25).
“I also doubt whether FB Custom Audiences work correctly with consent. FB finds out and retains a small bit of personal info through this process (that an email address they know is known to an advertiser), and they aim to shift the data protection legal justification on that to the advertisers. Do they really then not use this info for future profiling?”
That looming tweak to the legal justification of Facebook’s Custom Audiences feature — a product which lets advertisers upload contact lists in a hashed form to find any matches among its own user-base (so those people can be targeted with ads on Facebook’s platform) — also looks problematical.
Here the company seems to be intending to try to claim a change in the legal basis, pushed out via new terms in which it instructs advertisers to agree they are the data controller (and it is merely a data processor). And thereby seek to foist a greater share of the responsibility for obtaining consent to processing user data onto its customers.
However such legal determinations are simply not a matter of contract terms. They are based on the fact of who is making decisions about how data is processed. And in this case — as other experts have pointed out — Facebook would be classed as a joint controller with any advertisers that upload personal data. The company can’t use a T&Cs change to opt out of that.
Wishful thinking is not a reliable approach to legal compliance.
Fear and manipulation of highly sensitive data
Over many years of privacy-hostile operation, Facebook has shown it has a major appetite for even very sensitive data. And GDPR does not appear to have blunted that.
Let’s not forget, facial recognition was a platform feature that got turned off in the EU, thanks to regulatory intervention. Yet here Facebook is now trying to use GDPR as a route to process this sensitive biometric data for international users after all — by pushing individual users to consent to it by dangling a few ‘feature perks’ at the moment of consent.
Veteran data protection and privacy consultant, Pat Walshe, is unimpressed.
“The sensitive data tool appears to be another data grab,” he tells us, reviewing Facebook’s latest clutch of ‘GDPR changes’. “Note the subtlety. It merges ‘control of sharing’ such data with FB’s use of the data “to personalise features and products”. From the info available that isn’t sufficient to amount to consent for such sensitive data and nor is it clear folks can understand the broader implications of agreeing.
“Does it mean ads will appear in Instagram? WhatsApp etc? The default is also set to ‘accept’ rather than ‘review and consider’. This is really sensitive data we’re talking about.”
“The face recognition suggestions are woeful,” he continues. “The second image — is using an example… to manipulate and stoke fear — “we can’t protect you”.
“Also, the choices and defaults are not compatible with [GDPR] Article 25 on data protection by design and default nor Recital 32… If I say no to facial recognition it’s unclear if other users can continue to tag me.”
Of course it goes without saying that Facebook users will keep uploading group photos, not just selfies. What’s less clear is whether Facebook will be processing the faces of other people in those shots who have not given (and/or never even had the opportunity to give) consent to its facial recognition feature.
People who might not even be users of its product.
But if it does that it will be breaking the law. Yet Facebook does indeed profile non-users — despite Zuckerberg’s claims to Congress not to know about its shadow profiles. So the risk is clear.
It can’t give non-users “settings and controls” not to have their data processed. So it’s already compromised their privacy — because it never gained consent in the first place.
New Mexico Representative Ben Lujan made this point to Zuckerberg’s face last week and ended the exchange with a call to action: “So you’re directing people that don’t even have a Facebook page to sign up for a Facebook page to access their data… We’ve got to change that.”

WASHINGTON, DC – APRIL 11: Facebook co-founder, Chairman and CEO Mark Zuckerberg prepares to testify before the House Energy and Commerce Committee in the Rayburn House Office Building on Capitol Hill April 11, 2018 in Washington, DC. This is the second day of testimony before Congress by Zuckerberg, 33, after it was reported that 87 million Facebook users had their personal information harvested by Cambridge Analytica, a British political consulting firm linked to the Trump campaign. (Photo by Chip Somodevilla/Getty Images)
But nothing in the measures Facebook has revealed so far, as its ‘compliance response’ to GDPR, suggest it intends to pro-actively change that.
Walshe also critically flags how — again, at the point of consent — Facebook’s review process deploys examples of the social aspects of its platform (such as how it can use people’s information to “suggest groups or other features or products”) as a tactic for manipulating people to agree to share religious affiliation data, for example.
“The social aspect is not separate to but bound up in advertising,” he notes, adding that the language also suggests Facebook uses the data.
Again, this whiffs a whole lot more than smells like GDPR compliance.
“I don’t believe FB has done enough,” adds Walshe, giving a view on Facebook’s GDPR preparedness ahead of the May 25 deadline for the framework’s application — as Zuckerberg’s Congress briefing notes suggested the company itself believes it has. (Or maybe it just didn’t want to admit to Congress that U.S. Facebook users will get lower privacy standards vs users elsewhere.)
“In fact I know they have not done enough. Their business model is skewed against privacy — privacy gets in the way of advertising and so profit. That’s why Facebook has variously suggested people may have to pay if they want an ad free model & so ‘pay for privacy’.”
“On transparency, there is a long way to go,” adds Boiten. “Friend suggestions, profiling for advertising, use of data gathered from like buttons and web pixels (also completely missing from “all your Facebook data”), and the newsfeed algorithm itself are completely opaque.”
“What matters most is whether FB’s processing decisions will be GDPR compliant, not what exact controls are given to FB members,” he concludes.
US lawmakers also pumped Zuckerberg on how much of the information his company harvests on people who have a Facebook account is revealed to them when they ask for it — via its ‘Download your data’ tool.
His answers on this appeared to intentionally misconstrue what was being asked — presumably in a bid to mask the ugly reality of the true scope and depth of the surveillance apparatus he commands. (Sometimes with a few special ‘CEO privacy privileges’ thrown in — like being able to selectively retract just his own historical Facebook messages from conversations, ahead of bringing the feature to anyone else.)
‘Download your Data’ is clearly partial and self-serving — and thus it also looks very far from being GDPR compliant.
Not even half the story
Facebook is not even complying with the spirit of current EU data protection law on data downloads. Subject Access Requests give individuals the right to request not just the information they have voluntarily uploaded to a service, but also personal data the company holds about them; Including giving a description of the personal data; the reasons it is being processed; and whether it will be given to any other organizations or people.
Facebook not only does not include people’s browsing history in the info it provides when you ask to download your data — which, incidentally, its own cookies policy confirms it tracks (via things like social plug-ins and tracking pixels on millions of popular websites etc etc) — it also does not include a complete list of advertisers on its platform that have your information.
Instead, after a wait, it serves up an eight-week snapshot. But even this two month view can still stretch to hundreds of advertisers per individual.
If Facebook gave users a comprehensive list of advertisers’ access to their information the number of third party companies would clearly stretch into the thousands. (In some cases thousands might even be a conservative estimate.)
There’s plenty of other information harvested from users that Facebook also intentionally fails to divulge via ‘Download your data’. And — to be clear — this isn’t a new problem either. The company has a very long history of blocking these type of requests.
In the EU it currently invokes a exception in Irish law to circumvent more fulsome compliance — which, even setting GDPR aside, raises some interesting competition law questions, as Paul-Olivier Dehaye told the UK parliament last month.
“All your Facebook data” isn’t a complete solution,” agrees Boiten. “It misses the info Facebook uses for auto-completing searches; it misses much of the information they use for suggesting friends; and I find it hard to believe that it contains the full profiling information.”
“Ads Topics” looks rather random and undigested, and doesn’t include the clear categories available to advertisers,” he further notes.
Facebook wouldn’t comment publicly about this when we asked. But it maintains its approach towards data downloads is GDPR compliant — and says it’s reviewed what it offers via with regulators to get feedback.
Earlier this week it also put out a wordy blog post attempting to diffuse this line of attack by pointing the finger of blame at the rest of the tech industry — saying, essentially, that a whole bunch of other tech giants are at it too.
Which is not much of a moral defense even if the company believes its lawyers can sway judges with it. (Ultimately I wouldn’t fancy its chances; the EU’s top court has a robust record of defending fundamental rights.)
Think of the children…
What its blog post didn’t say — yet again — was anything about how all the non-users it nonetheless tracks around the web are able to have any kind of control over its surveillance of them.
And remember, some Facebook non-users will be children.
So yes, Facebook is inevitably tracking kids’ data without parental consent. Under GDPR that’s a majorly big no-no.
TC’s Constine had a scathing assessment of even the on-platform system that Facebook has devised in response to GDPR’s requirements on parental consent for processing the data of users who are between the ages of 13 and 15.
“Users merely select one of their Facebook friends or enter an email address, and that person is asked to give consent for their ‘child’ to share sensitive info,” he observed. “But Facebook blindly trusts that they’ve actually selected their parent or guardian… [Facebook’s] Sherman says Facebook is “not seeking to collect additional information” to verify parental consent, so it seems Facebook is happy to let teens easily bypass the checkup.”
So again, the company is being shown doing the minimum possible — in what might be construed as a cynical attempt to check another compliance box and carry on its data-sucking business as usual.
Given that intransigence it really will be up to the courts to bring the enforcement stick. Change, as ever, is a process — and hard won.
Hildebrandt is at least hopeful that a genuine reworking of Internet business models is on the way, though — albeit not overnight. And not without a fight.
“In the coming years the landscape of all this silly microtargeting will change, business models will be reinvented and this may benefit both the advertisers, consumers and citizens,” she tells us. “It will hopefully stave off the current market failure and the uprooting of democratic processes… Though nobody can predict the future, it will require hard work.”



 And an ALS medication currently in development — which Mulvaney says will aim to significantly extend the prospects for those who have been diagnosed with ALS — is about five years away from trials. It’s worth the effort to try, though: the best ALS medications on the market today at best only add about three month’s to a patient’s life expectancy.
And an ALS medication currently in development — which Mulvaney says will aim to significantly extend the prospects for those who have been diagnosed with ALS — is about five years away from trials. It’s worth the effort to try, though: the best ALS medications on the market today at best only add about three month’s to a patient’s life expectancy.

 By two years, it will have imaged 85 percent of the sky — hundreds of times the area Kepler observed, and on completely different stars: brighter ones that should yield more data.
By two years, it will have imaged 85 percent of the sky — hundreds of times the area Kepler observed, and on completely different stars: brighter ones that should yield more data.