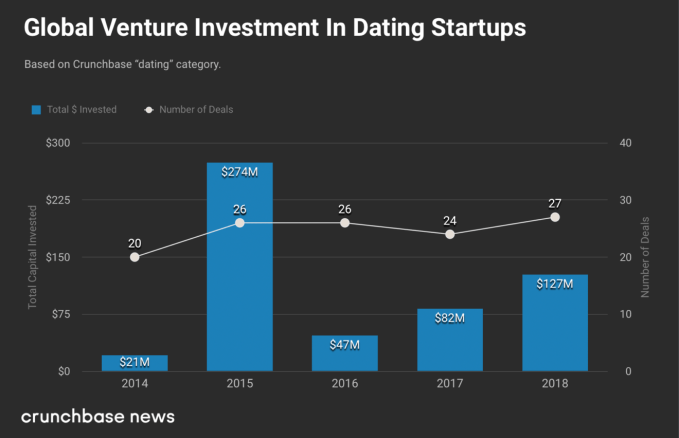
A final report by a British parliamentary committee which spent months last year investigating online political disinformation makes very uncomfortable reading for Facebook — with the company singled out for “disingenuous” and “bad faith” responses to democratic concerns about the misuse of people’s data.
In the report, published today, the committee has also called for Facebook’s use of user data to be investigated by the UK’s data watchdog.
In an evidence session to the committee late last year, the Information Commissioner’s Office (ICO) suggested Facebook needs to change its business model — warning the company risks burning user trust for good.
Last summer the ICO also called for an ethical pause of social media ads for election campaigning, warning of the risk of developing “a system of voter surveillance by default”.
Interrogating the distribution of ‘fake news’
The UK parliamentary enquiry looked into both Facebook’s own use of personal data to further its business interests, such as by providing access to user data to developers and advertisers in order to increase revenue and/or usage; and examined what Facebook claimed as ‘abuse’ of its platform by the disgraced (and now defunct) political data company Cambridge Analytica — which in 2014 paid a developer with access to Facebook’s developer platform to extract information on millions of Facebook users in build voter profiles to try to influence elections.
The committee’s conclusion about Facebook’s business is a damning one with the company accused of operating a business model that’s predicated on selling abusive access to people’s data.
“Far from Facebook acting against “sketchy” or “abusive” apps, of which action it has produced no evidence at all, it, in fact, worked with such apps as an intrinsic part of its business model,” the committee argues. “This explains why it recruited the people who created them, such as Joseph Chancellor [the co-founder of GSR, the developer which sold Facebook user data to Cambridge Analytica]. Nothing in Facebook’s actions supports the statements of Mark Zuckerberg who, we believe, lapsed into “PR crisis mode”, when its real business model was exposed.
“This is just one example of the bad faith which we believe justifies governments holding a business such as Facebook at arms’ length. It seems clear to us that Facebook acts only when serious breaches become public. This is what happened in 2015 and 2018.”
“We consider that data transfer for value is Facebook’s business model and that Mark Zuckerberg’s statement that ‘we’ve never sold anyone’s data” is simply untrue’,” the committee also concludes.
We’ve reached out to Facebook for comment on the committee’s report.
Last fall the company was issued the maximum possible fine under relevant UK data protection law for failing to safeguard user data from Cambridge Analytica saga. Although Facebook is appealing the ICO’s penalty, claiming there’s no evidence UK users’ data got misused.
During the course of a multi-month enquiry last year investigating disinformation and fake news, the Digital, Culture, Media and Sport (DCMS) committee heard from 73 witnesses in 23 oral evidence sessions, as well as taking in 170 written submissions. In all the committee says it posed more than 4,350 questions.
Its wide-ranging, 110-page report makes detailed observations on a number of technologies and business practices across the social media, adtech and strategic communications space, and culminates in a long list of recommendations for policymakers and regulators — reiterating its call for tech platforms to be made legally liable for content.
Among the report’s main recommendations are:
- clear legal liabilities for tech companies to act against “harmful or illegal content”, with the committee calling for a compulsory Code of Ethics overseen by a independent regulatory with statutory powers to obtain information from companies; instigate legal proceedings and issue (“large”) fines for non-compliance
- privacy law protections to cover inferred data so that models used to make inferences about individuals are clearly regulated under UK data protection rules
- a levy on tech companies operating in the UK to support enhanced regulation of such platforms
- a call for the ICO to investigate Facebook’s platform practices and use of user data
- a call for the Competition Markets Authority to comprehensively “audit” the online advertising ecosystem, and also to investigate whether Facebook specifically has engaged in anti-competitive practices
- changes to UK election law to take account of digital campaigning, including “absolute transparency of online political campaigning” — including “full disclosure of the targeting used” — and more powers for the Electoral Commission
- a call for a government review of covert digital influence campaigns by foreign actors (plus a review of legislation in the area to consider if it’s adequate) — including the committee urging the government to launch independent investigations of recent past elections to examine “foreign influence, disinformation, funding, voter manipulation, and the sharing of data, so that appropriate changes to the law can be made and lessons can be learnt for future elections and referenda”
- a requirement on social media platforms to develop tools to distinguish between “quality journalism” and low quality content sources, and/or work with existing providers to make such services available to users
Among the areas the committee’s report covers off with detailed commentary are data use and targeting; advertising and political campaigning — including foreign influence; and digital literacy.
It argues that regulation is urgently needed to restore democratic accountability and “make sure the people stay in charge of the machines”.
Ministers are due to produce a White Paper on social media safety regulation this winter and the committee writes that it hopes its recommendations will inform government thinking.
“Much has been said about the coarsening of public debate, but when these factors are brought to bear directly in election campaigns then the very fabric of our democracy is threatened,” the committee writes. “This situation is unlikely to change. What does need to change is the enforcement of greater transparency in the digital sphere, to ensure that we know the source of what we are reading, who has paid for it and why the information has been sent to us. We need to understand how the big tech companies work and what happens to our data.”
The report calls for tech companies to be regulated as a new category “not necessarily either a ‘platform’ or a ‘publisher”, but which legally tightens their liability for harmful content published on their platforms.
Last month another UK parliamentary committee also urged the government to place a legal ‘duty of care’ on platforms to protect users under the age of 18 — and the government said then that it has not ruled out doing so.
“Digital gangsters”
Competition concerns are also raised several times by the committee.
“Companies like Facebook should not be allowed to behave like ‘digital gangsters’ in the online world, considering themselves to be ahead of and beyond the law,” the DCMS committee writes, going on to urge the government to investigate whether Facebook specifically has been involved in any anti-competitive practices and conduct a review of its business practices towards other developers “to decide whether Facebook is unfairly using its dominant market position in social media to decide which businesses should succeed or fail”.
“The big tech companies must not be allowed to expand exponentially, without constraint or proper regulatory oversight,” it adds.
The committee suggests existing legal tools are up to the task of reining in platform power, citing privacy laws, data protection legislation, antitrust and competition law — and calling for a “comprehensive audit” of the social media advertising market by the UK’s Competition and Markets Authority, and a specific antitrust probe of Facebook’s business practices.
“If companies become monopolies they can be broken up, in whatever sector,” the committee points out. “Facebook’s handling of personal data, and its use for political campaigns, are prime and legitimate areas for inspection by regulators, and it should not be able to evade all editorial responsibility for the content shared by its users across its platforms.”
The social networking giant was the recipient of many awkward queries during the course of the committee’s enquiry but it refused repeated requests for its founder Mark Zuckerberg to testify — sending a number of lesser staffers in his stead.
That decision continues to be seized upon by the committee as evidence of a lack of democratic accountability. It also accuses Facebook of having an intentionally “opaque management structure”.
“By choosing not to appear before the Committee and by choosing not to respond personally to any of our invitations, Mark Zuckerberg has shown contempt towards both the UK Parliament and the ‘International Grand Committee’, involving members from nine legislatures from around the world,” the committee writes.
“The management structure of Facebook is opaque to those outside the business and this seemed to be designed to conceal knowledge of and responsibility for specific decisions. Facebook used the strategy of sending witnesses who they said were the most appropriate representatives, yet had not been properly briefed on crucial issues, and could not or chose not to answer many of our questions. They then promised to follow up with letters, which—unsurprisingly—failed to address all of our questions. We are left in no doubt that this strategy was deliberate.”
It doubles down on the accusation that Facebook sought to deliberately mislead its enquiry — pointing to incorrect and/or inadequate responses from staffers who did testify.
“We are left with the impression that either [policy VP] Simon Milner and [CTO] Mike Schroepfer deliberately misled the Committee or they were deliberately not briefed by senior executives at Facebook about the extent of Russian interference in foreign elections,” it suggests.
In an unusual move late last year the committee used rare parliamentary powers to seize a cache of documents related to an active US lawsuit against Facebook filed by a developer called Six4Three.
The cache of documents is referenced extensively in the final report, and appears to have fuelled antitrust concerns, with the committee arguing that the evidence obtained from the internal company documents “indicates that Facebook was willing to override its users’ privacy settings in order to transfer data to some app developers, to charge high prices in advertising to some developers, for the exchange of that data, and to starve some developers… of that data, thereby causing them to lose their business”.
“It seems clear that Facebook was, at the very least, in violation of its Federal Trade Commission [privacy] settlement,” the committee also argues, citing evidence from the former chief technologist of the FTC, Ashkan Soltani .
On Soltani’s evidence, it writes:
Ashkan Soltani rejected [Facebook’s] claim, saying that up until 2012, platform controls did not exist, and privacy controls did not apply to apps. So even if a user set their profile to private, installed apps would still be able to access information. After 2012, Facebook added platform controls and made privacy controls applicable to apps. However, there were ‘whitelisted’ apps that could still access user data without permission and which, according to Ashkan Soltani, could access friends’ data for nearly a decade before that time. Apps were able to circumvent users’ privacy of platform settings and access friends’ information, even when the user disabled the Platform. This was an example of Facebook’s business model driving privacy violations.
While Facebook is singled out for the most eviscerating criticism in the report (and targeted for specific investigations), the committee’s long list of recommendations are addressed at social media businesses and online advertisers generally.
It also calls for far more transparency from platforms, writing that: “Social media companies need to be more transparent about their own sites, and how they work. Rather than hiding behind complex agreements, they should be informing users of how their sites work, including curation functions and the way in which algorithms are used to prioritise certain stories, news and videos, depending on each user’s profile. The more people know how the sites work, and how the sites use individuals’ data, the more informed we shall all be, which in turn will make choices about the use and privacy of sites easier to make.”
The committee also urges a raft of updates to UK election law — branding it “not fit for purpose” in the digital era.
Its interim report, published last summer, made many of the same recommendations.
Russian interest
But despite pressing the government for urgent action there was only a cool response from ministers then, with the government remaining tied up trying to shape a response to the 2016 Brexit vote which split the country (with social media’s election-law-deforming help). Instead it opted for a ‘wait and see‘ approach.
The government accepted just three of the preliminary report’s forty-two recommendations outright, and fully rejected four.
Nonetheless, the committee has doubled down on its preliminary conclusions, reiterating earlier recommendations and pushing the government once again to act.
It cites fresh evidence, including from additional testimony, as well as pointing to other reports (such as the recently published Cairncross Review) which it argues back up some of the conclusions reached.
“Our inquiry over the last year has identified three big threats to our society. The challenge for the year ahead is to start to fix them; we cannot delay any longer,” writes Damian Collins MP and chair of the DCMS Committee, in a statement. “Democracy is at risk from the malicious and relentless targeting of citizens with disinformation and personalised ‘dark adverts’ from unidentifiable sources, delivered through the major social media platforms we use every day. Much of this is directed from agencies working in foreign countries, including Russia.
“The big tech companies are failing in the duty of care they owe to their users to act against harmful content, and to respect their data privacy rights. Companies like Facebook exercise massive market power which enables them to make money by bullying the smaller technology companies and developers who rely on this platform to reach their customers.”
“These are issues that the major tech companies are well aware of, yet continually fail to address. The guiding principle of the ‘move fast and break things’ culture often seems to be that it is better to apologise than ask permission. We need a radical shift in the balance of power between the platforms and the people,” he added.
“The age of inadequate self-regulation must come to an end. The rights of the citizen need to be established in statute, by requiring the tech companies to adhere to a code of conduct written into law by Parliament, and overseen by an independent regulator.”
The committee says it expects the government to respond to its recommendations within two months — noting rather dryly: “We hope that this will be much more comprehensive, practical, and constructive than their response to the Interim Report, published in October 2018. Several of our recommendations were not substantively answered and there is now an urgent need for the Government to respond to them.”
It also makes a point of including an analysis of Internet traffic to the government’s own response to its preliminary report last year — in which it highlights a “high proportion” of online visitors hailing from Russian cities including Moscow and Saint Petersburg…
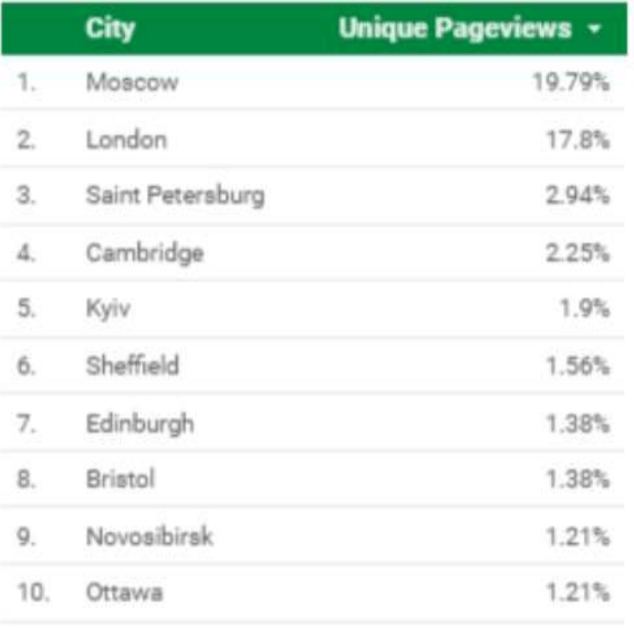
Source: Web and publications unit, House of Commons
“This itself demonstrates the very clear interest from Russia in what we have had to say about their activities in overseas political campaigns,” the committee remarks, criticizing the government response to its preliminary report for claiming there’s no evidence of “successful” Russian interference in UK elections and democratic processes.
“It is surely a sufficient matter of concern that the Government has acknowledged that interference has occurred, irrespective of the lack of evidence of impact. The Government should be conducting analysis to understand the extent of Russian targeting of voters during elections,” it adds.
Three senior managers knew
Another interesting tidbit from the report is confirmation that the ICO has shared the names of three “senior managers” at Facebook who knew about the Cambridge Analytica data breach prior to the first press report in December 2015 — which is the date Facebook has repeatedly told the committee was when it first learnt of the breach, contradicting what the ICO found via its own investigations.
The committee’s report does not disclose the names of the three senior managers — saying the ICO has asked the names to remain confidential (we’ve reached out to the ICO to ask why it is not making this information public) — and implies the execs did not relay the information to Zuckerberg.
The committee dubs this as an example of “a profound failure” of internal governance, and also branding it evidence of “fundamental weakness” in how Facebook manages its responsibilities to users.
Here’s the committee’s account of that detail:
We were keen to know when and which people working at Facebook first knew about the GSR/Cambridge Analytica breach. The ICO confirmed, in correspondence with the Committee, that three “senior managers” were involved in email exchanges earlier in 2015 concerning the GSR breach before December 2015, when it was first reported by The Guardian. At the request of the ICO, we have agreed to keep the names confidential, but it would seem that this important information was not shared with the most senior executives at Facebook, leading us to ask why this was the case.
The scale and importance of the GSR/Cambridge Analytica breach was such that its occurrence should have been referred to Mark Zuckerberg as its CEO immediately. The fact that it was not is evidence that Facebook did not treat the breach with the seriousness it merited. It was a profound failure of governance within Facebook that its CEO did not know what was going on, the company now maintains, until the issue became public to us all in 2018. The incident displays the fundamental weakness of Facebook in managing its responsibilities to the people whose data is used for its own commercial interests.