Israeli cloud security firm Orca Security today announced a $55 million Series B funding round led by ICONIQ Growth. Previous investors GGV Capital, YL Ventures and Silicon Valley CISO Investments also participated in the round, which brings the company’s total funding to date to $82 million. This includes Orca’s $20.5 million Series A round, which it announced in May.
What makes Orca stand out is not just its focus on cloud-native technologies but what it calls its SideScanning technology. This enables it to map a company’s cloud environment and reconstruct its file system by looking at how workloads interact with the block storage services they use. Based on this, in combination with the cloud metadata it collects, it can map and scan a company’s entire data estate and its cloud assets — and find potential security issues. Because of this system, Orca also immediately discovers new hosts in the cloud without anybody having to maintain this part of the system.
This means the system can work without any agents, too, and hence without introducing any additional overhead into the existing systems. That, Orca Security CEO Avi Shua argues, wouldn’t have been possible in an on-premises setting.
“The way it works is that — without installing any agents or running anything on the environment — it reads the block storage of your flow from the side to deduce the risk and it builds maps of your environment so you can see it in context,” Shua, who spent 11 years working at Check Point before launching Orca, explained. “Both of these things simply were not possible in the on-premise environment because you need to install agents to see. And when you install an agent, it sees the tree, it doesn’t see the forest. It isn’t able to understand where traffic comes from, it doesn’t understand that if it sees a key, what that key opens.”
Orca Security Team
He also noted that Orca wants to be as comprehensive as possible so that companies don’t have to use different tools for detecting misconfigurations, malware, vulnerabilities, etc. The company also aims to make the process of getting started with its technology frictionless. Indeed, Shua argues that the Achilles heel of the whole industry is that companies get to maybe 50 percent of coverage if they work hard, but then hit a brick wall because deploying a lot of security tools can be quite hard. “Usually people are not getting breached because the walls are not high enough but because they are not covering the thing that they’re trying to protect,” Shua said.
Orca also aims to provide security practitioners with relevant alerts based on the context of the exposure and business impact. A company may be running a lot of software that is vulnerable to remote code execution in the NTP service, for example. But the environment doesn’t expose NTP and it’s blocked by default in all of the company’s security groups, so while this may look like a major vulnerability in the overall stack, it doesn’t actually represent a real risk. Shua told me of a customer who, after installing Orca, found more than a million critical issues. The company’s tools helped the security team reduce those to 33 that it should focus on.
“The common denominator amongst just about every company we see is that the solutions are very complex — the problems they’re trying to solve are complex and the solutions tend to be complex,” GGV Capital managing partner Glenn Solomon told me. “One of the amazing things about Orca is — and I think that this is a result of Avi and Gil [Geron] and the rest of the co-founders having a lot of experience at Check Point — they understood from day one like that a big part of the value here is being able to install and just provide value really quickly and seamlessly.”
The service currently supports AWS, Google Cloud Platform and Microsoft Azure and their various container services.
Image Credits: Orca Security
Clearly, Orca has hit on a winning formula here. Shua tells me that the company grew more than 10x this year already and instead of growing the team to about 50 employees, it’s already at 70 now. At one point this summer, simply scheduling a call with a salesperson at Orca could take three weeks. Given this, it’s maybe no surprise that Orca wanted to raise to continue to accelerate this growth (and that VCs would want to put more money into the company).
“This massive $55 million round will really help propel Orca to cloud security dominance,” YL Ventures managing partner Yoav Leitersdorf told me. “Already year-over-year growth is stunning — higher than anything I’ve ever seen — literally hundreds of percent. They are incredibly unique in the market with their SideScanning technology.”
The company plans to use the new funding to increase continue building out its product and increase its sales and marketing efforts. In addition, Orca plans to increase its R&D efforts and open a number of new sales offices around the world.
As TC readers know, the tricky trade-off of the modern web is privacy for convenience. Online tracking is how this ‘great intimacy robbery’ is pulled off. Mass surveillance of what Internet users are looking at underpins Google’s dominant search engine and Facebook’s social empire, to name two of the highest profile ad-funded business models.
TechCrunch’s own corporate overlord, Verizon, also gathers data from a variety of end points — mobile devices, media properties like this one — to power its own ad targeting business.
Countless others rely on obtaining user data to extract some perceived value. Few if any of these businesses are wholly transparent about how much and what sort of private intelligence they’re amassing — or, indeed, exactly what they’re doing with it. But what if the web didn’t have to be like that?
Berlin-based Xayn wants to change this dynamic — starting with personalized but privacy-safe web search on smartphones.
Today it’s launching a search engine app (on Android and iOS) that offers the convenience of personalized results but without the ‘usual’ shoulder surfing. This is possible because the app runs on-device AI models that learn locally. The promise is no data is ever uploaded (though trained AI models themselves can be).
The team behind the app, which is comprised of 30% PhDs, has been working on the core privacy vs convenience problem for some six years (though the company was only founded in 2017); initially as an academic research project — going on to offer an open source framework for masked federated learning, called XayNet. The Xayn app is based on that framework.
They’ve raised some €9.5 million in early stage funding to date — with investment coming from European VC firm Earlybird; Dominik Schiener (Iota co-founder); and the Swedish authentication and payment services company, Thales AB.
Now they’re moving to commercialize their XayNet technology by applying it within a user-facing search app — aiming for what CEO and co-founder, Dr Leif-Nissen Lundbæk bills as a “Zoom”-style business model, in reference to the ubiquitous videoconferencing tool which has both free and paid users.
This means Xayn’s search is not ad-supported. That’s right; you get zero ads in search results.
Instead, the idea is for the consumer app to act as a showcase for a b2b product powered by the same core AI tech. The pitch to business/public sector customers is speedier corporate/internal search without compromising commercial data privacy.
Lundbæk argues businesses are sorely in need of better search tools to (safely) apply to their own data, saying studies have shown that search in general costs around 18% of working time globally. He also cites a study by one city authority that found staff spent 37% of their time at work searching for documents or other digital content.
“It’s a business model that Google has tried but failed to succeed,” he argues, adding: “We are solving not only a problem that normal people have but also that companies have… For them privacy is not a nice to have; it needs to be there otherwise there is no chance of using anything.”
On the consumer side there will also be some premium add-ons headed for the app — so the plan is for it to be a freemium download.
Swipe to nudge the algorithm
One key thing to note is Xayn’s newly launched web search app gives users a say in whether the content they’re seeing is useful to them (or not).
It does this via a Tinder-style swipe right (or left) mechanic that lets users nudge its personalization algorithm in the right direction — starting with a home screen populated with news content (localized by country) but also extending to the search result pages.
The news-focused homescreen is another notable feature. And it sounds like different types of homescreen feeds may be on the premium cards in future.
Another key feature of the app is the ability to toggle personalized search results on or off entirely — just tap the brain icon at the top right to switch the AI off (or back on). Results without the AI running can’t be swiped, except for bookmarking/sharing.
Elsewhere, the app includes a history page which lists searches from the past seven days (by default). The other options offered are: Today, 30 days, or all history (and a bin button to purge searches).
There’s also a ‘Collections’ feature that lets you create and access folders for bookmarks.
As you scroll through search results you can add an item to a Collection by swiping right and selecting the bookmark icon — which then opens a prompt to choose which one to add it to.
The swipe-y interface feels familiar and intuitive, if slightly laggy to load content in the TestFlight beta version TechCrunch checked out ahead of launch.
Swiping left on a piece of content opens a bright pink color-block stamped with a warning ‘x’. Keep going and you’ll send the item vanishing into the ether, presumably seeing fewer like it in future.
Whereas a swipe right affirms a piece of content is useful. This means it stays in the feed, outlined in Xayn green. (Swiping right also reveals the bookmark option and a share button.)
While there are pro-privacy/non-tracking search engines on the market already — such as US-based DuckDuckGo or France’s Qwant — Xayn argues the user experience of such rivals tends to fall short of what you get with a tracking search engine like Google, i.e. in terms of the relevance of search results and thus time spent searching.
Simply put: You probably have to spend more time ‘DDGing’ or ‘Qwanting’ to get the specific answers you need vs Googling — hence the ‘convenience cost’ associated with safeguarding your privacy when web searching.
Xayn’s contention is there’s a third, smarter way of getting to keep your ‘virtual clothes’ on when searching online. This involves implementing AI models that learn on-device and can be combined in a privacy-safe way so that results can be personalized without putting people’s data at risk.
“Privacy is the very fundament… It means that quite like other privacy solutions we track nothing. Nothing is sent to our servers; we don’t store anything of course; we don’t track anything at all. And of course we make sure that any connection that is there is basically secured and doesn’t allow for any tracking at all,” says Lundbæk, explaining the team’s AI-fuelled, decentralized/edge-computing approach.
On-device reranking
Xayn is drawing on a number of search index sources, including (but not solely) Microsoft’s Bing, per Lundbæk, who described this bit of what it’s doing as “relatively similar” to DuckDuckGo (which has its own web crawling bots).
The big difference is that it’s also applying its own reranking algorithms in order generate privacy-safe personalized search results (whereas DDG uses a contextual ads-based business model — looking at simple signals like location and keyword search to target ads without needing to profile users).
The downside to this sort of approach, according to Lundbæk, is users can get flooded with ads — as a consequence of the simpler targeting meaning the business serves more ads to try to increase chances of a click. And loads of ads in search results obviously doesn’t make for a great search experience.
“We get a lot of results on device level and we do some ad hoc indexing — so we build on the device level and on index — and with this ad hoc index we apply our search algorithms in order to filter them, and only present you what is more relevant and filter out everything else,” says Lundbæk, sketching how Xayn works. “Or basically downgrade it a bit… but we also try to keep it fresh and explore and also bump up things where they might not be super relevant for you but it gives you some guarantees that you won’t end up in some kind of bubble.”
Some of what Xayn’s doing is in the arena of federated learning (FL) — a technology Google has been dabbling in in recent years, including pushing a ‘privacy-safe’ proposal for replacing third party tracking cookies. But Xayn argues the tech giant’s interests, as a data business, simply aren’t aligned with cutting off its own access to the user data pipe (even if it were to switch to applying FL to search).
Whereas its interests — as a small, pro-privacy German startup — are markedly different. Ergo, the privacy-preserving technology it’s spent years building has a credible interest in safeguarding people’s data, is the claim.
“At Google there’s actually [fewer] people working on federate learning than in our team,” notes Lundbæk, adding: “We’ve been criticizing TFF [Google-designed TensorFlow Federated] at lot. It is federated learning but it’s not actually doing any encryption at all — and Google has a lot of backdoors in there.
“You have to understand what does Google actually want to do with that? Google wants to replace [tracking] cookies — but especially they want to replace this kind of bumpy thing of asking for user consent. But of course they still want your data. They don’t want to give you any more privacy here; they want to actually — at the end — get your data even easier. And with purely federated learning you actually don’t have a privacy solution.
“You have to do a lot in order to make it privacy preserving. And pure TFF is certainly not that privacy-preserving. So therefore they will use this kind of tech for all the things that are basically in the way of user experience — which is, for example, cookies but I would be extremely surprised if they used it for search directly. And even if they would do that there is a lot of backdoors in their system so it’s pretty easy to actually acquire the data using TFF. So I would say it’s just a nice workaround for them.”
“Data is basically the fundamental business model of Google,” he adds. “So I’m sure that whatever they do is of course a nice step in the right direction… but I think Google is playing a clever role here of kind of moving a bit but not too much.”
So how, then, does Xayn’s reranking algorithm work?
The app runs four AI models per device, combining encrypted AI models of respective devices asynchronously — with homomorphic encryption — into a collective model. A second step entails this collective model being fed back to individual devices to personalize served content, it says.
The four AI models running on the device are one for natural language processing; one for grouping interests; one for analyzing domain preferences; and one for computing context.
“The knowledge is kept but the data is basically always staying on your device level,” is how Lundbæk puts it.
“We can simply train a lot of different AI models on your phone and decide whether we, for example, combine some of this knowledge or whether it also stays on your device.”
“We have developed a quite complex solution of four different AI models that work in composition with each other,” he goes on, noting that they work to build up “centers of interest and centers of dislikes” per user — again, based on those swipes — which he says “have to be extremely efficient — they have to be moving, basically, also over time and with your interests”.
The more the user interacts with Xayn, the more precise its personalization engine gets as a result of on-device learning — plus the added layer of users being able to get actively involved by swiping to give like/dislike feedback.
The level of personalization is very individually focused — Lundbæk calls it “hyper personalization” — more so than a tracking search engine like Google, which he notes also compares cross-user patterns to determine which results to serve — something he says Xayn absolutely does not do.
Small data, not big data
“We have to focus entirely on one user so we have a ‘small data’ problem, rather than a big data problem,” says Lundbæk. “So we have to learn extremely fast — only from eight to 20 interactions we have to already understand a lot from you. And the crucial thing is of course if you do such a rapid learning then you have to take even more care about filter bubbles — or what is called filter bubbles. We have to prevent the engine going into some kind of biased direction.”
To avoid this echo chamber/filter bubble type effect, the Xayn team has designed the engine to function in two distinct phases which it switches between: Called ‘exploration’ and (more unfortunately) ‘exploitation’ (i.e. just in the sense that it already knows something about the user so can be pretty certain what it serves will be relevant).
“We have to keep fresh and we have to keep exploring things,” he notes — saying that’s why it developed one of the four AIs (a dynamic contextual multi-armed bandit reinforcement learning algorithm for computing context).
Aside from this app infrastructure being designed natively to protect user privacy, Xayn argues there are a bunch of other advantages — such as being able to derive potentially very clear interests signs from individuals; and avoiding the chilling effect that can result from tracking services creeping users out (to the point people they avoid making certain searches in order to prevent them from influencing future results).
“You as the user can decide whether you want the algorithm to learn — whether you want it to show more of this or less of this — by just simply swiping. So it’s extremely easy, so you can train your system very easily,” he argues.
There is potentially a slight downside to this approach, too, though — assuming the algorithm (when on) does some learning by default (i.e in the absence of any life/dislike signals from the user).
This is because it puts the burden on the user to interact (by swiping their feedback) in order to get the best search results out of Xayn. So that’s an active requirement on users, rather than the typical passive background data mining and profiling web users are used to from tech giants like Google (which is, however, horrible for their privacy).
It means there’s an ‘ongoing’ interaction cost to using the app — or at least getting the most relevant results out of it. You might not, for instance, be advised to let a bunch of organic results just scroll past if they’re really not useful but rather actively signal disinterest on each.
For the app to be the most useful it may ultimately pay to carefully weight each item and provide the AI with a utility verdict. (And in a competitive battle for online convenience every little bit of digital friction isn’t going to help.)
Asked about this specifically, Lundbæk told us: “Without swiping the AI only learns from very weak likes but not from dislikes. So the learning takes place (if you turn the AI on) but it’s very slight and does not have a big effect. These conditions are quite dynamic, so from the experience of liking something after having visited a website, patterns are learned. Also, only 1 of the 4 AI models (the domain learning one) learns from pure clicks; the others don’t.”
Xayn does seem alive to the risk of the swiping mechanic resulting in the app feeling arduous. Lundbæk says the team is looking to add “some kind of gamification aspect” in the future — to flip the mechanism from pure friction to “something fun to do”. Though it remains to be seen what they come up with on that front.
There is also inevitably a bit of lag involved in using Xayn vs Google — by merit of the former having to run on-device AI training (whereas Google merely hoovers your data into its cloud where it’s able to process it at super-speeds using dedicated compute hardware, including bespoke chipsets).
“We have been working for over a year on this and the core focus point was bringing it on the street, showing that it works — and of course it is slower than Google,” Lundbæk concedes.
“Google doesn’t need to do any of these [on-device] processes and Google has developed even its own hardware; they developed TPUs exactly for processing this kind of model,” he goes on. “If you compare this kind of hardware it’s pretty impressive that we were even able to bring [Xayn’s on-device AI processing] even on the phone. However of course it’s slower than Google.”
Lundbæk says the team is working on increasing the speed of Xayn. And anticipates further gains as it focuses more on that type of optimization — trailing a version that’s 40x faster than the current iteration.
“It won’t at the end be 40x faster because we will use this also to analyze even more content — to give you can even broader view — but it will be faster over time,” he adds.
On the accuracy of search results vs Google, he argues the latter’s ‘network effect’ competitive advantage — whereby its search reranking benefits from Google having more users — is not unassailable because of what edge AI can achieve working smartly atop ‘small data’.
Though, again, for now Google remains the search standard to beat.
“Right now we compare ourselves, mostly against Bing and DuckDuckGo and so on. Obviously there we get much better results [than compared to Google] but of course Google is the market leader and is using quite some heavy personalization,” he says, when we ask about benchmarking results vs other search engines.
“But the interesting thing is so far Google is not only using personalization but they also use kind of a network effect. PageRank is very much a network effect where the most users they have the better the results get, because they track how often people click on something and bump this also up.
“The interesting effect there is that right now, through AI technology — like for example what we use — the network effect becomes less and less important. So actually I would say that there isn’t really any network effect anymore if you really want to compete with pure AI technology. So therefore we can get almost as relevant results as Google right now and we surely can also, over time, get even better results or competing results. But we are different.”
In our (brief) tests of the beta app Xayn’s search results didn’t obviously disappoint for simple searches (and would presumably improve with use). Though, again, the slight load lag adds a modicum of friction which was instantly obvious compared to the usual search competition.
Not a deal breaker — just a reminder that performance expectations in search are no cake walk (even if you can promise a cookie-free experience).
“So far Google has so far had the advantage of a network effect — but this network effect gets less and less dominant and you see already more and more alternatives to Google popping up,” Lundbæk argues, suggesting privacy concerns are creating an opportunity for increased competition in the search space.
“It’s not anymore like Facebook or so where there’s one network where everyone has to be. And I think this is actually a nice situation because competition is always good for technical innovations and for also satisfying different customer needs.”
Of course the biggest challenge for any would-be competitor to Google search — which carves itself a marketshare in Europe in excess of 90% — is how to poach (some of) its users.
Lundbæk says the startup has no plans to splash millions on marketing at this point. Indeed, he says they want to grow usage sustainably, with the aim of evolving the product “step by step” with a “tight community” of early adopters — relying on cross-promotion from others in the pro-privacy tech space, as well as reaching out to relevant influencers.
He also reckons there’s enough mainstream media interest in the privacy topic to generate some uplift.
“I think we have such a relevant topic — especially now,” he says. “Because we want to show also not only for ourselves that you can do this for search but we think we show a real nice example that you can do this for any kind of case.
“You don’t always need the so-called ‘best’ big players from the US which are of course getting all of your data, building up profiles. And then you have these small, cute privacy-preserving solutions which don’t use any of this but then offer a bad user experience. So we want to show that this shouldn’t be the status quo anymore — and you should start to build alternatives that are really build on European values.”
And it’s certainly true EU lawmakers are big on tech sovereignty talk these days, even though European consumers mostly continue to embrace big (US) tech.
Perhaps more pertinently, regional data protection requirements are making it increasing challenging to rely on US-based services for processing data. Compliance with the GDPR data protection framework is another factor businesses need to consider. All of which is driving attention onto ‘privacy-preserving’ technologies.
Xayn’s team is hoping to be able spread its privacy-preserving gospel to general users by growing the b2b side of the business, according to Lundbæk — so it’s hoping some home use will follow once employees get used to convenient private search via their workplaces, in a small-scale reverse of the business consumerization trend that was powered by modern smartphones (and people bringing their own device to work).
“We these kind of strategies I think we can step by step build up in our communities and spread the word — so we think we don’t even need to really spend millions of euros in marketing campaigns to get more and more users,” he adds.
While Xayn’s initial go-to-market push has been focused on getting the mobile apps out, a desktop version is also planned for Q1 next year.
The challenge there is getting the app to work as a browser extension as the team obviously doesn’t want to build its own browser to house Xayn. tl;dr: Competing with Google search is mountain enough to climb, without trying to go after Chrome (and Firefox, and so on).
“We developed our entire AI in Rust which is a safe language. We are very much driven by security here and safety. The nice thing is it can work everywhere — from embedded systems towards mobile systems, and we can compile into web assembly so it runs also as a browser extension in any kind of browser,” he adds. “Except for Internet Explorer of course.”
While the enterprise world likes to talk about “big data”, that term belies the real state of how data exists for many organizations: the truth of the matter is that it’s often very fragmented, living in different places and on different systems, making the concept of analysing and using it in a single, effective way a huge challenge.
Today, one of the big up-and-coming startups that has built a platform to get around that predicament is announcing a significant round of funding, a sign of the demand for its services and its success so far in executing on that.
SingleStore, which provides a SQL-based platform to help enterprises manage, parse and use data that lives in silos across multiple cloud and on-premise environments — a key piece of work needed to run applications in risk, fraud prevention, customer user experience, real-time reporting and real-time insights, fast dashboards, data warehouse augmentation, modernization for data warehouses and data architectures and faster insights — has picked up $80 million in funding, a Series E round that brings in new strategic investors alongside its existing list of backers.
The round is being led by Insight Partners, with new backers Dell Technologies Capital, Hercules Capital; and previous backers Accel, Anchorage, Glynn Capital, GV (formerly Google Ventures) and Rev IV also participating.
Alongside the investment, SingleStore is formally announcing a new partnership with analytics powerhouse SAS. I say “formally” because they two have been working together already and it’s resulted in “tremendous uptake,” CEO Raj Verma said in an interview over email.
Verma added that the round came out of inbound interest, not its own fundraising efforts, and as such, it brings the total amount of cash it has on hand to $140 million. The gives the startup money to play with not only to invest in hiring, R&D and business development, but potentially also M&A, given that the market right now seems to be in a period of consolidation.
Verma said the valuation is a “significant upround” compared to its Series D in 2018 but didn’t disclose the figure. PitchBook notes that at the time it was valued at $270 million post-money.
When I last spoke with the startup in May of this year — when it announced a debt facility of $50 million — it was not called SingleStore; it was MemSQL. The company rebranded at the end of October to the new name, but Verma said that the change was a long time in the planning.
“The name change is one of the first conversations I had when I got here,” he said about when he joined the company in 2019 (he’s been there for about 16 months). “The [former] name didn’t exactly flow off the tongue and we found that it no longer suited us, we found ourselves in a tiny shoebox of an offering, in saying our name is MemSQL we were telling our prospects to think of us as in-memory and SQL. SQL we didn’t have a problem with but we had outgrown in-memory years ago. That was really only 5% of our current revenues.”
He also mentioned the hang up many have with in-memory database implementations: they tend to be expensive. “So this implied high TCO, which couldn’t have been further from the truth,” he said. “Typically we are ⅕-⅛ the cost of what a competitive product would be to implement. We were doing ourselves a disservice with prospects and buyers.”
The company liked the name SingleStore because it is based a conceptual idea of its proprietary technology. “We wanted a name that could be a verb. Down the road we hope that when someone asks large enterprises what they do with their data, they will say that they ‘SingleStore It!’ That is the vision. The north star is that we can do all types of data without workload segmentation,” he said.
That effort is being done at a time when there is more competition than ever before in the space. Others also providing tools to manage and run analytics and other work on big data sets include Amazon, Microsoft, Snowflake, PostgreSQL, MySQL and more.
SingleStore is not disclosing any metrics on its growth at the moment but says it has thousands of enterprise customers. Some of the more recent names it’s disclosed include GE, IEX Cloud, Go Guardian, Palo Alto Networks, EOG Resources, SiriusXM + Pandora, with partners including Infosys, HCL and NextGen.
“As industry after industry reinvents itself using software, there will be accelerating market demand for predictive applications that can only be powered by fast, scalable, cloud-native database systems like SingleStore’s,” said Lonne Jaffe, managing director at Insight Partners, in a statement. “Insight Partners has spent the past 25 years helping transformational software companies rapidly scale-up, and we’re looking forward to working with Raj and his management team as they bring SingleStore’s highly differentiated technology to customers and partners across the world.”
“Across industries, SAS is running some of the most demanding and sophisticated machine learning workloads in the world to help organizations make the best decisions. SAS continues to innovate in AI and advanced analytics, and we partner with companies like SingleStore that share our curiosity about how data and analytics can help organizations reimagine their businesses and change the world,” said Oliver Schabenberger, COO and CTO at SAS, added. “Our engineering teams are integrating SingleStore’s scalable SQL-based database platform with the massively parallel analytics engine SAS Viya. We are excited to work with SingleStore to improve performance, reduce cost, and enable our customers to be at the forefront of analytics and decisioning.”
Cybersecurity insurance startup At-Bay has raised $34 million in its Series C round, the company announced Tuesday.
The round was led by Qumra Capital, a new investor. Microsoft’s venture fund M12, also a new investor, participated in the round alongside Acrew Capital, Khosla Ventures, Lightspeed Venture Partners, Munich Re Ventures, and Israeli entrepreneur Shlomo Kramer, who co-founded security firms Check Point and Imperva.
It’s a huge move for the company, which only closed its Series B in February.
The cybersecurity insurance market is expected to become a $23 billion industry by 2025, driven in part by an explosion in connected devices and new regulatory regimes under Europe’s GDPR and more recently California’s state-wide privacy law. But where traditional insurance companies have struggled to acquire the acumen needed to accommodate the growing demand for cybersecurity insurance, startups like At-Bay have filled the space.
At-Bay was founded in 2016 by Rotem Iram and Roman Itskovich, and is headquartered in Mountain View. In the past year, the company has tripled its headcount and now has offices in New York, Atlanta, Chicago, Portland, Los Angeles, and Dallas.
The company differentiates itself from the pack by monitoring the perimeter of its customers’ networks and alerting them to security risks or vulnerabilities. By proactively looking for potential security issues, At-Bay helps its customers to prevent network intrusions and data breaches before they happen, avoiding losses for the company while reducing insurance payouts — a win-win for both the insurance provider and its customers.
“This modern approach to risk management is not only driving strong demand for our insurance, but also enabling us to improve our products and minimize loss to our insureds,” said Iram.
It’s a bet that’s paying off: the company says its frequency of claims are less than half of the industry average. Lior Litwak, a partner at M12, said he sees “immense potential” in the company for melding cyber risk and analysis with cyber insurance.
Now with its Series C in the bank, the company plans to grow its team and launch new products, while improving its automated underwriting platform that allows companies to get instant cyber insurance quotes.
Round of applause for the Bureau of Investigative Journalism — which fought for two years to obtain details of a closed door meeting between Facebook’s Mark Zuckerberg and the UK secretary of state in charge of digital issues at the time, Matt Hancock (now health secretary).
Freedom of information requests for minutes of the 2018 closed-door meeting between Zuckerberg and Hancock, which took place amist Cambridge Analytica-related tensions, were repeatedly refused by the Department for Digital, Media, Culture and Sport (DCMS).
An order by the UK’s Information Commissioner’s Office finally forced the government to hand them over — with the ICO concluding that transparency and openness are clearly in the public interest where Facebook’s business and CEO is concerned.
Last year the UK government set out an intent to regulate online platforms, publishing its Online Harms White Paper — which proposes to place a legal duty of care on social media platforms to protect users against a range of harms, from bullying to illegal content. Although there’s no sign of a draft law.
The government has only said it will lay one before parliament ‘as soon as possible’. (And this summer refused to commit to doing so next year.)
It’s now clear that Zuckerberg took time to meet privately with Hancock, on the sidelines of the Paris VivaTech conference in late May 2018.
There, according to the minutes obtained by the Bureau, the Facebook CEO accused the UK of having an “anti-tech government” — and joked about making it one of two countries he would not visit. (The other is redacted from the documents but may have been a reference to China.)
Zuckerberg also threatened to pull Facebook’s investment from the UK — saying that while it was the “obvious” place for them to invest in Europe they were now “considering looking elsewhere”.
The tech giant employs thousands of staff at its London base, which is a major engineering hub for the company.
At the start of this year Facebook announced it would add another 1,000 jobs — bringing its total headcount up to 4,000+ in the city. A new HQ it’s preparing in London’s King’s Cross, to consolidate its existing London offices, is intended to house 6,000 staff in total when running at full capacity.
Per the minutes, Hancock responded to Zuckerberg by offering “a new beginning” for the government’s relationship with social media platforms — and offered to change its approach from “threatening regulation to encouraging collaborative working to ensure legislation is proportionate and innovation-friendly”.
He is also said to have sought “increased dialogue” with Zuckerberg — in order to “bring forward the message that he has support from Facebook at the highest level”.
While Zuckerberg is reported to have expressed support for UK policy and its intent to regulate the Internet — but said he was “worried about tone”.
We’ve reached out to DCMS for comment on the meeting and remarks made by its former digital secretary and to ask why it fought disclosure of the information for two years. We’ll update this report with any response.
Around the time Zuckerberg met Hancock Facebook employed around 2,300 staff in the UK. The tech giant signed the lease on the King’s Cross office space in July 2018 — a few months after Zuckerberg’s meeting with Hancock — generating headlines which couched it as a ‘major vote of confidence in the UK capital‘.
Reached for comment on the revelations that Zuckerberg branded the UK “anti-tech” and threatened to pull the plug on its local investments, Facebook sent us this statement — attributed to ‘a spokesperson’:
Facebook has long said we need new regulations to set high standards across the internet. In fact last year Mark Zuckerberg called on governments to establish new rules around harmful content, privacy, data portability, and election integrity. The UK is our largest engineering hub outside of the US and just this year we created 1,000 new roles in the country.
Also responding to the Bureau’s story in a series of tweets today, Damian Collins, the former chair of the DMCS committee said the minutes show Facebook did not like the inquiry; and that Zuckerberg was “determined not to appear as a witness”.
Collins was highly critical of Zuckerberg’s refusal to testify to the UK parliament, issuing a summons for him to do so on May 1, 2018 should he ever deign to step onto UK soil, and publicly lambasting the company for displaying an evasive “pattern of behavior”.
The note of the meeting between Mark Zuckerburg & Matt Hancock in May 2018, 2 months after the Cambridge Analytica scandal, and published today by @TBIJ shows Facebook didn’t like the @CommonsDCMS inquiry I chaired & that Mark Zuckerberg was determined not to appear as a witness pic.twitter.com/0GdQDKmfxi
“The context of Mark Zuckerberg’s 2018 meeting with Matt Hancock was that it was two months after the Cambridge Analytica scandal had broken and MZ was refusing our requests for him to appear before [DCMS committee] to discuss it,” Collins tweeted.
“The notes from this meeting clearly show that Mark Zuckerberg was running scared of the DCMS committee investigation on disinformation and fake news and was actively seeking to avoid being questioned by us about what he knew and when about the Cambridge Analytica scandal.”
“It shows how afraid Mark Zuckerberg is of scrutiny that Facebook saw questions about the safety of users data on their platform, and how they worked with Cambridge Analytica as an ‘anti-tech’ agenda,” he added.
Outstanding questions related to the Cambridge Analytica include how much and when Zuckerberg personally knew about the scandal. It has previously emerged that Facebook staff raised internal alerts about Cambridge Analytica’s activity as early as September 2015 — yet the company was not booted off its ad platform until 2018.
A Facebook-instigated post-scandal app audit has also never fully reported findings.
Nor do we know why the tech giant hired the co-founder of the company that sold user data to Cambridge Analytica — around the same time it heard about the ‘sketchy’ company.
Zuckerberg’s question dodging over his personal level of responsibility vis-a-vis the scandal has been highly successful, even as his business empire has faced increased scrutiny and lawmakers around the world have new appetite to regulate the Internet.
The UK’s ICO issue no final report on its own investigation into the data misuse scandal. But in a letter to the DCMS committee in October it confirmed Facebook user data had been transferred to Cambridge Analytica and incorporated into a pre-existing database containing “voter file, demographic and consumer data for US individuals” — with the aim of predicting partisanship to target US voters with political messaging.
The ICO’s investigation did not find any evidence that the Facebook data which was sold to Cambridge Analytica had been used to target voters in the UK’s Brexit Referendum vote.
In its final report for the disinformation inquiry, the DCMS called for Facebook’s business to be investigated — citing competition and data protection concerns.
Last month the UK government announced a plan to set up a “pro-competition” regulator for big tech.
The AirPods Max are joining the AirPods and AirPods Pro in Apple’s audio accessory lineup. As you can see on the photo, Apple is releasing its first over-ear headphones under the AirPods brand.
The wireless headphones feature active noise cancellation and cost $549. With this product, Apple competes directly with Sony’s and Bose’s wireless headphones — the Sony WH-1000XM4 and Bose 700. Pre-orders start today and they’ll ship on December 15.
This isn’t the company’s first over-ear headphones as Apple acquired Beats back in 2014. Apple has released new Beats headphones over the past few years. For instance, last year, Apple released the Beats Solo Pro, wireless headphones that feature Apple’s H1 chip and cost $300. They also have active noise cancellation.
The AirPods Max come in multiple colors — silver, space gray, sky blue, pink and green. They are foldable and can be stored in a case — or, as Apple calls it, a Smart Case.
Powered by Apple’s H1 chip, they bring many of the features that you can find in the AirPods Pro — active noise cancellation, transparency mode, spatial audio and adaptive EQ. The headband is made of stainless steel, which probably explains the pricing strategy. The ear cushions try to create a seal thanks to memory foam.
In addition to a noise control button, there’s an Apple Watch digital crown, which lets you adjust the volume, skip tracks, etc.
SpaceX is all set to conduct a high-altitude test of its Starship rocket – a first for the spacecraft prototype design. The test will see Starship serial number 8 (SN8) fly from SpaceX’s development site in Cameron County, Texas, climb to a max height of around 41,000 feet, and then return to Earth during a controlled landing using its Raptor engines, if all goes exactly to plan. SpaceX CEO Elon Musk has noted that things likely won’t go exactly to plan with this test, saying he anticipates they’ll achieve maybe 1/3 of their goals with this attempt.
This is the first time that Starship will be flying with three Raptor engines on board – prior short hop tests of earlier prototypes used just one. It’ll also involve a key maneuver that the Starship will ultimately be required to get right in order to achieve its reusability goal and return safely through Earth’s atmosphere when landing – a mid-air belly flop of sorts to orient it correctly to avoid burning up during re-entry.
SpaceX has flown Starship prototypes to a height of just under 500 feet, and successfully landed both with a controlled descent. This attempt will also include an attempt to relight Starship’s engines and return it to Earth in a vertical orientation, but those are much less likely to be successful at this stage vs. the earlier stage goals just reaching that max altitude and then ideally completing that ‘belly flop’ maneuver. Conducting tests like this with low likelihood of successful outcomes is absolutely par for the course for rocket development programs, but SpaceX is one of the few companies that conducts these out in the open – and perhaps the only that does so with live-streamed access for all.
Ultimately, Starship will prove the central component of a new generation of launch vehicle that SpaceX hopes to use to reach Mars – and to replace all of its current launch activities with Falcon vehicles, as well as to provide high-altitude point-to-point flights between destinations on Earth for hyper-fast travel. The production Starship will be paired with a Super Heavy rocket for additional thrust for high mass cargo missions and long-duration deep space trips.
The test launch today could happen anytime between roughly 9 AM EST (6 AM PST) and 6 PM EST (3 PM PST), and SpaceX says that it will begin the livestream shortly before the actual launch attempt, so stay tuned to the video above and our Twitter account for updates.
Companies like Stripe and Twilio have changed the game for online businesses by making it easier to integrate payments and communications services into their customer interfaces without having to build those features from the ground up, or make costly investments to integrate them from elsewhere. Today, another startup is launching and announcing some funding in the hopes that it can do the same for financial features.
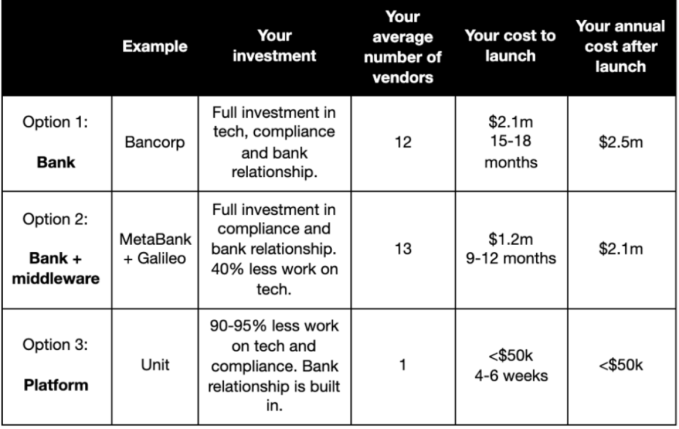
Unit has built a platform that lets third parties integrate banking services like payment cards, checking accounts, cash advances and money transfers into their own businesses by way of an API. And after quietly building the service (and a customer base) in stealth, the company today is announcing that it is open for business with $18.6 million in funding alongside that to continue growing — by adding in more features, hiring more people, and securing new users.
The capital is coming from a mix of investors that speak to the company’s Israeli roots and current San Francisco base. It includes Better Tomorrow Ventures, Aleph, Flourish Ventures, Operator Partners and TLV Partners, as well as 30 angels drawing on a pool of fintech experience among them.
CEO Itai Damti, who co-founded the company with Doron Somech (who is the CTO) said that the company’s mission is to make it easier for companies that have customers already doing some kind of transacting work with customers — for example, an on-demand transportation company interacting with its fleet of contract drivers; or an online bookkeeping platform providing services to users — to extend that into a wider and deeper and mor loyal relationship with more financial features.
“Companies in the freelancer economy are in the great position to bundle more banking services into their platforms for freelancers,” Damti said. Indeed many of these have dabbled in the past with providing other services such as payment cards as a way of paying out their commissions. Now, “it means they can help their freelancers track spending, as well as send payments to them.”
His belief is that by making it easier to incorporate these features, we will see a veritable explosion of businesses lining up to do so. “We have already seen a lot of pickup,” he said.
Large, incumbent banks have been relatively slow to bring their services up to speed with the pace of change in the world of tech, and that has opened the door to a number of challengers hoping to gain market share by providing more personalised services, more flexibility and better rates, all by way of efficient mobile apps rather than through queues in old buildings.
Unit’s bet is that there is an even bigger opportunity to provide banking services if you can identify places where people are doing work already. The global health pandemic, in its estimation, has increased that push simply because it’s bringing more people online than ever before, and they are looking towards the internet to get more work done than ever before.
The catch is that up to now, for companies that are not specifically in the business of fintech to provide those services, the costs — monetary, time, and labor — have been too high to make services viable. Unit says that its API-based solution solves that issue:
There are other companies that have identified the opportunity of “financial services as a service” and are growing at a fast pace tapping into that market.
One of the most notable, perhaps, is Rapyd, which was last valued at $1.2 billion about a year ago, with backers including the likes of Stripe alongside many other top investors.
Stripe, indeed, itself recently teamed up with banks to start an embedded business banking service of its own, Stripe Treasury, which underscores also the growing competition in this space.
But with ever-more business coming online, for now at least there remains an opportunity for everyone.
“Tech and non-financial companies are embedding financial services with an eye towards deepening customer relationships and enhancing unit economics,” said Emmalyn Shaw of Flourish Ventures in a statement. “This is a precarious move if not done right. Financial services are carefully regulated, demanding best in class compliance available from Unit. Executives, including Amanda Swoverland, former Chief Risk Officer at Sunrise Bank, position Unit to offer the highest quality compliance and frictionless integration for enterprises of all sizes.”
“True innovation in financial services requires a technical partner that straddles the finance and the technology part of fintech, and none do it better than Unit. We’ve backed many fintech companies through the years and think many of the next generation of companies will be built on top of Unit,” added Sheel Mohnot of Better Tomorrow Ventures.
In the past few months AppHarvest, a developer of greenhouse tomato farms went public through a special purpose acquisition vehicle, vertical farming giant Plenty raised $140 million, and now Gotham Greens, which is developing its own network of greenhouses, is announcing the close of $87 million in new funding.
These new agriculture companies certainly have a green thumb when it comes to raising a cornucopia of capital.
Gotham Greens latest round takes the company to a whopping total of $130 million in funding since its launch. Investors in the round included Manna Tree and The Silverman Group.
While App Harvest has taken to tomatoes in its attempt to ketchup with the leading agricultural companies, Gotham Greens has decided to let its hydroponically grown leafy greens lead the way to riches.
The company said it would use the latest funding to continue developing more greenhouse across the U.S. and bring new vegetables to market.
“Given increasing challenges facing centralized food supply chains, combined with rapidly shifting consumer preferences, Gotham Greens is focused on expanding its regional growing operations and distribution capabilities at one of the most critical periods for America,” said Viraj Puri, the co-founder and chief executive of Gotham Greens, in a statement.
The company already sells its greens in over 40 states and operates greenhouses in Chicago, Providence, R.I., Baltimore and Denver. From those greenhouses the company distributes to 2,000 retail locations including Whole Foods Markets, Albertsons stores, Meijer, Target, King Soopers, Harris Teeter, ShopRite and Sprouts.
And Gotham Greens has already begun to expand its product portfolio. The company now sells packaged salads, cooking sauces, and salad bowls in addition to its greens.
Assorted packages of Gotham Greens lettuces on a white field. Image Credit: Gotham Greens
Carsome, which bills itself as Southeast Asia’s largest e-commerce platform for used cars, announced it has closed a $30 million Series D. The funding was led by Asia Partners, with participation from returning investors Burda Principal Investments and Ondine Capital.
The startup claims that this is one of the largest “all-equity financings to-date in Southeast Asia’s online automotive industry.” Part of the Series D may be used for mergers and acquisitions to consolidate the company’s supply chain.
Founded five years ago in Malaysia, Carsome’s platform serves both C2C and B2C segments, and ensures quality by conducting inspections before vehicles are listed on its platform. It now has 1,000 employees and claims to transact 70,000 cars on an annualized basis, totaling $600 million.
In a press statement, co-founder and group chief executive officer Eric Cheng said that the company, which now also operates in Indonesia, Thailand and Singapore, doubled its monthly revenue over the past six months, compared to pre-pandemic levels. The company claims that this is partly because more people and businesses are buying their own cars for safety reasons.
While sales of new vehicles have plummeted around the world, used car sales, especially through e-commerce platforms, are recovering more quickly, according to Counterpoint Research. This largely because people want to avoid public transportation and ride-hailing, but also want cheaper options.
Other used car platforms in Southeast Asia include Carro, OLX Autos (formerly called BeliMobilGue) and Carmudi.

 Orca also aims to provide security practitioners with relevant alerts based on the context of the exposure and business impact. A company may be running a lot of software that is vulnerable to remote code execution in the NTP service, for example. But the environment doesn’t expose NTP and it’s blocked by default in all of the company’s security groups, so while this may look like a major vulnerability in the overall stack, it doesn’t actually represent a real risk. Shua told me of a customer who, after installing Orca, found more than a million critical issues. The company’s tools helped the security team reduce those to 33 that it should focus on.
Orca also aims to provide security practitioners with relevant alerts based on the context of the exposure and business impact. A company may be running a lot of software that is vulnerable to remote code execution in the NTP service, for example. But the environment doesn’t expose NTP and it’s blocked by default in all of the company’s security groups, so while this may look like a major vulnerability in the overall stack, it doesn’t actually represent a real risk. Shua told me of a customer who, after installing Orca, found more than a million critical issues. The company’s tools helped the security team reduce those to 33 that it should focus on.