YouTube today announced it’s launching a new feature that will push commenters to reconsider their hateful and offensive remarks before posting. It will also begin testing a filter that allows creators to avoid having to read some of the hurtful comments on their channel that had been automatically held for review. The new features are meant to address long standing issues with the quality of comments on YouTube’s platform — a problem creators have complained about for years.
The company said it will also soon run a survey aimed at giving equal opportunity to creators, and whose data can help the company to better understand how some creators are more disproportionately impacted by online hate and harassment.
The new commenting feature, rolling out today, is a significant change for YouTube.
The feature appears when users are about to post something offensive in a video’s comments section and warns to “Keep comments respectful.” The message also tells users to check the site’s Community Guidelines if they’re not sure if a comment is appropriate.
The pop-up then nudges users to click the “Edit” button and revise their comment by making “Edit” the more prominent choice on the screen that appears.
The feature will not actually prevent a user from posting their comment, however. If they want to proceed, they can click the “Post Anyway” option instead.
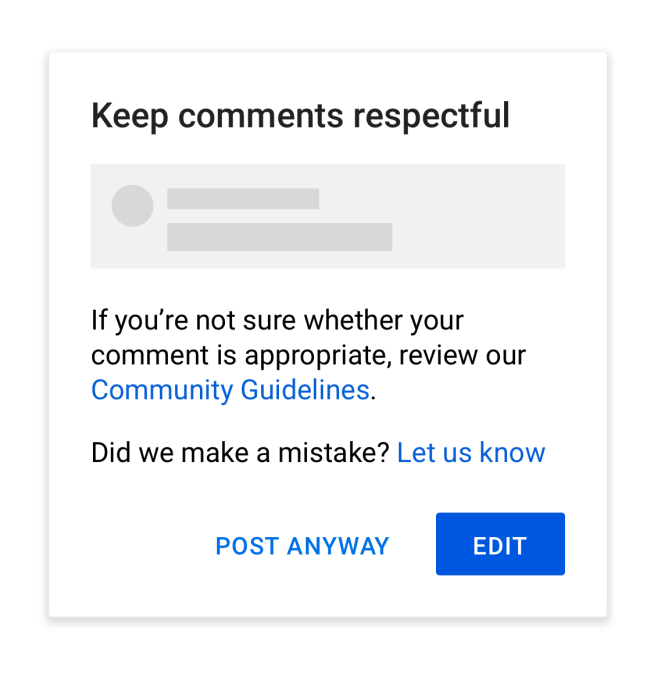
Image Credits: YouTube
The idea to put up roadblocks to give users time to pause and reconsider their words and actions is something several social media platforms are now doing.
For instance, Instagram last year launched a feature that would flag offensive comments before they were posted. It later expanded that to include offensive captions. Without providing data, the company claimed that these “nudges” were helping to reduce online bullying. Meanwhile, Twitter this year began to push users to read the article linked in tweets they were about to share before tweeting their reaction, and it stopped users from being able to retweet with just one click.
These intentional pauses built into the social platforms are designed to stop people from reacting to content with heightened emotion and anger, and instead push users to be more thoughtful in what they say and do. User interface changes like this leverage basic human psychology to work, and may even prove effective in some percentage of cases. But platforms have been hesitant to roll out such tweaks as they can stifle user engagement.
In YouTube’s case, the company tells TechCrunch its systems will learn what’s considered offensive based on what content gets repeatedly flagged by users. Over time, this A.I.-powered system should be able to improve as the technology gets better at detection and the system itself is further developed.
Users on Android in the English language will see the new prompts first, starting today, Google says. The rollout will complete over the next couple of days. The company did not offer a timeframe for the feature’s support for other platforms and languages or even a firm commitment that such support would arrive in the future.
In addition, YouTube said it will also now begin testing a feature for creators who use YouTube Studio to manage their channel.
Creators will be able to try out a new filter that will hide the offensive and hurtful comments that have automatically been held for review.
Today, YouTube Studio users can choose to auto-moderate potentially inappropriate comments, which they can then manually review and choose to approve, hide or report. While it’s helpful to have these held, it’s still often difficult for creators to have to deal with these comments at all, as online trolls can be unbelievably cruel. With the filter, creators can avoid these potentially offensive comments entirely.
YouTube says it will also streamline its moderation tools to make the review process easier going forward.
The changes follow a year during which YouTube has been heavily criticized for not doing enough to combat hate speech and misinformation on its platform. The video platform’s “strikes” system for rule violations means that videos may be individually removed but a channel itself can stay online unless it collects enough strikes to be taken down. In practice, that means a YouTube creator could be as violent as calling for government officials to be beheaded and and still continue to use YouTube. (By comparison, that same threat led to an account ban on Twitter.)
YouTube claims it has increased the number of daily hate speech comment removals by 46x since early 2019. And in the last quarter, of the more than 1.8 million channels it terminated for violating our policies, more than 54,000 terminations were for hate speech. That indicates a growing problem with online discourse that likely influenced these new measures. Some would argue the platforms have a responsibility to do even more, but it’s a difficult balance.
In a separate move, YouTube said it’s soon introducing a new survey that will ask creators to voluntarily share with YouTube information about their gender, sexual orientation, race and ethnicity. Using the data collected, YouTube claims it will be able to better examine how content from different communities is treated in search, discovery and monetization systems.
It will also look for possible patterns of hate, harassment, and discrimination that could affect some communities more than others, the company explains. And the survey will give creators to optionally participate in other initiatives that YouTube hosts, like #YouTubeBlack creator gatherings or FanFest, for instance.
This survey will begin in 2021 and was designed in consultation with input from creators and civil and human rights experts. YouTube says the collected data will not be used for advertising purposes, and creators will have the ability to opt-out and delete their information entirely at any time.